Molili帮大家一键部署安装了OpenClaw,同时还帮忙配置了几个实用的大模型,大家上手就能直接使用了,不过有不少朋友想要外接大模型,那么Molili可以外接大模型使用吗?Molili怎么外接大模型呢?下面就就来全面了解一下。
Molili可以外接大模型使用吗
可以,Molili可以外接大模型使用,不过需要一定的操作,有几种方法可以外接不同的大模型使用。
Molili怎么外接大模型
方法一:外接大模型API
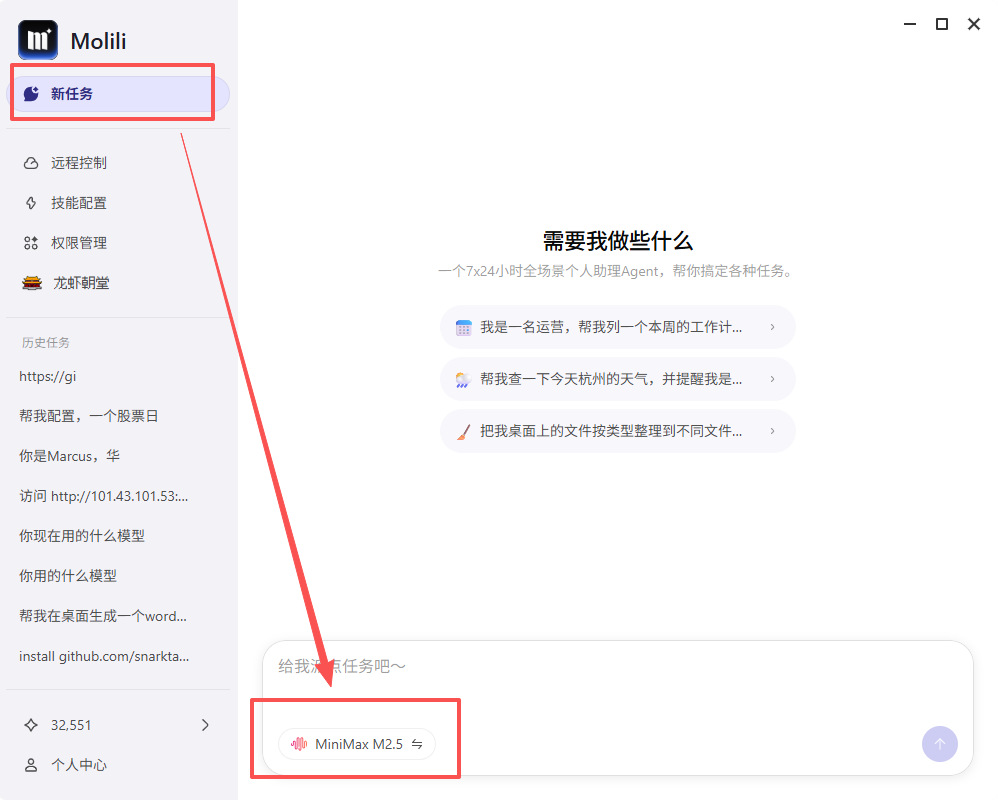
1、打开模型选择
在Molili的对话栏点击模型打开大模型选择界面;
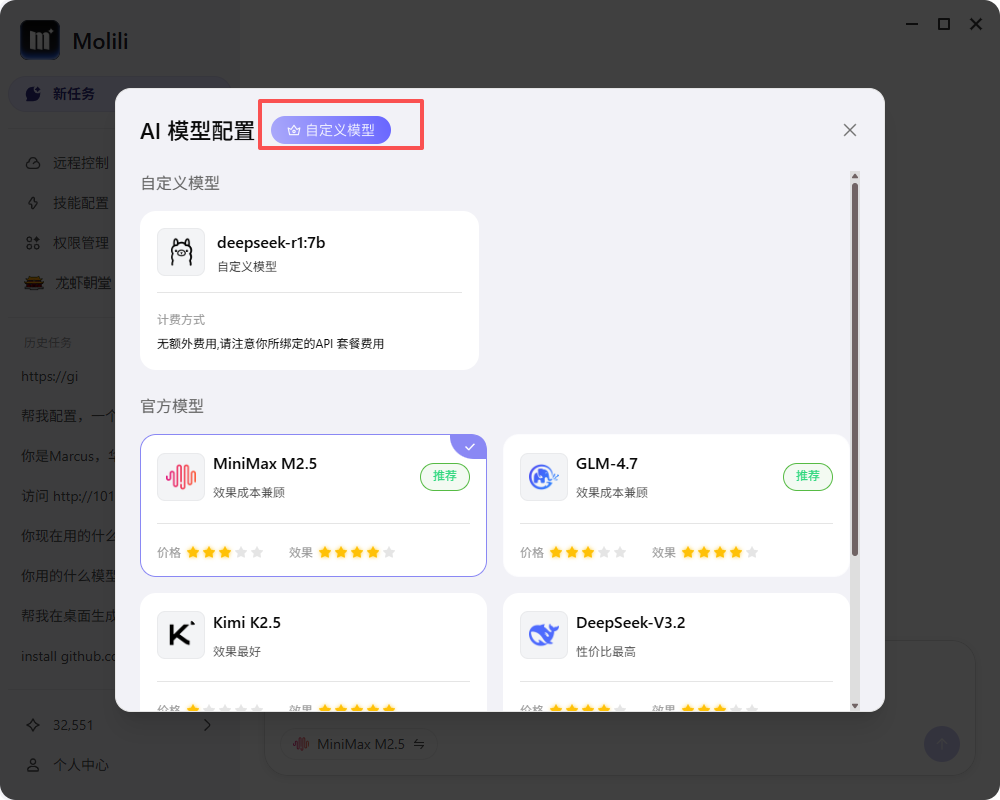
2、选择自定义模型
在模型选择界面点击上方的自定义模型开启自定义模型界面;
3、配置模型API
选择需要外接的大模型类型,然后输入大模型API进行连接即可。
方法二:连接本地大模型
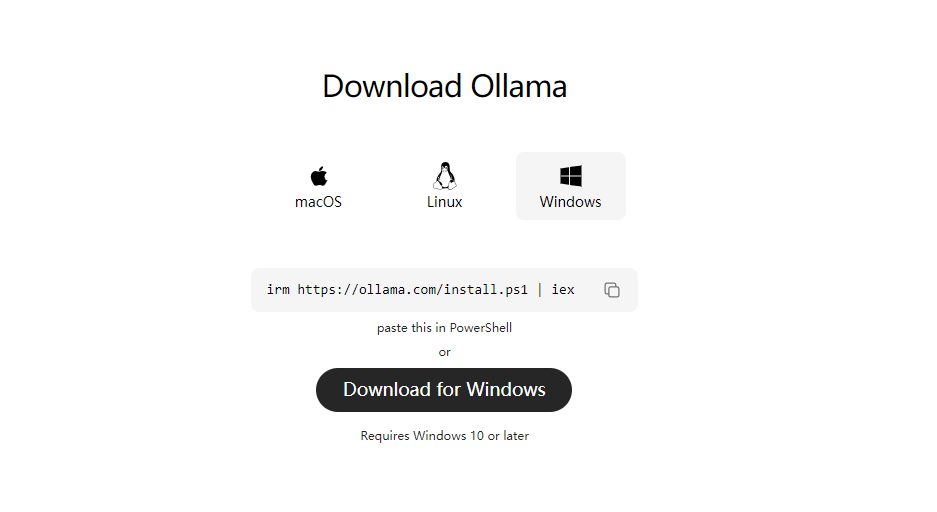
1、安装ollama
在ollama官网下载安装ollama安装包,或者通过指令安装;
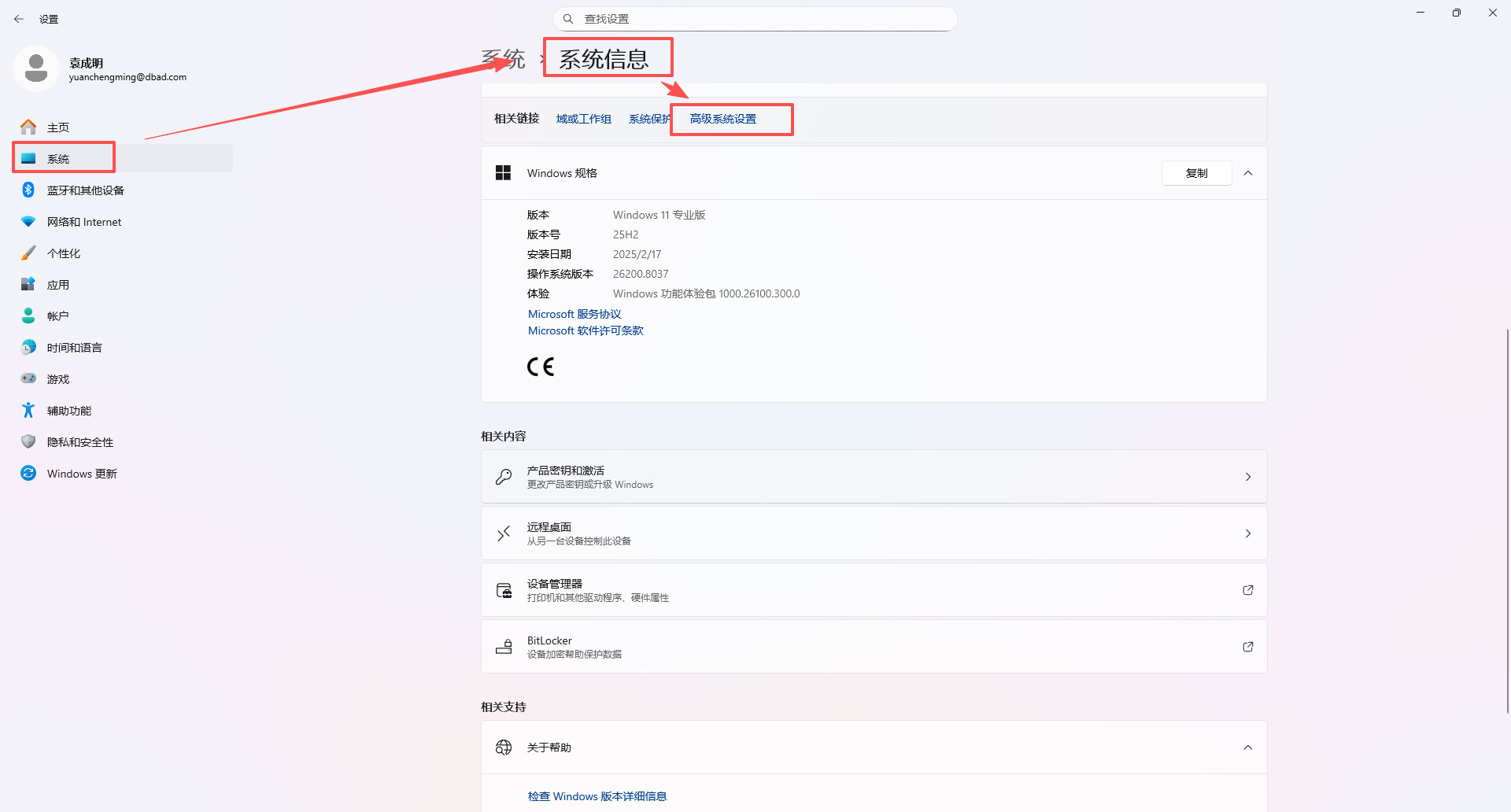
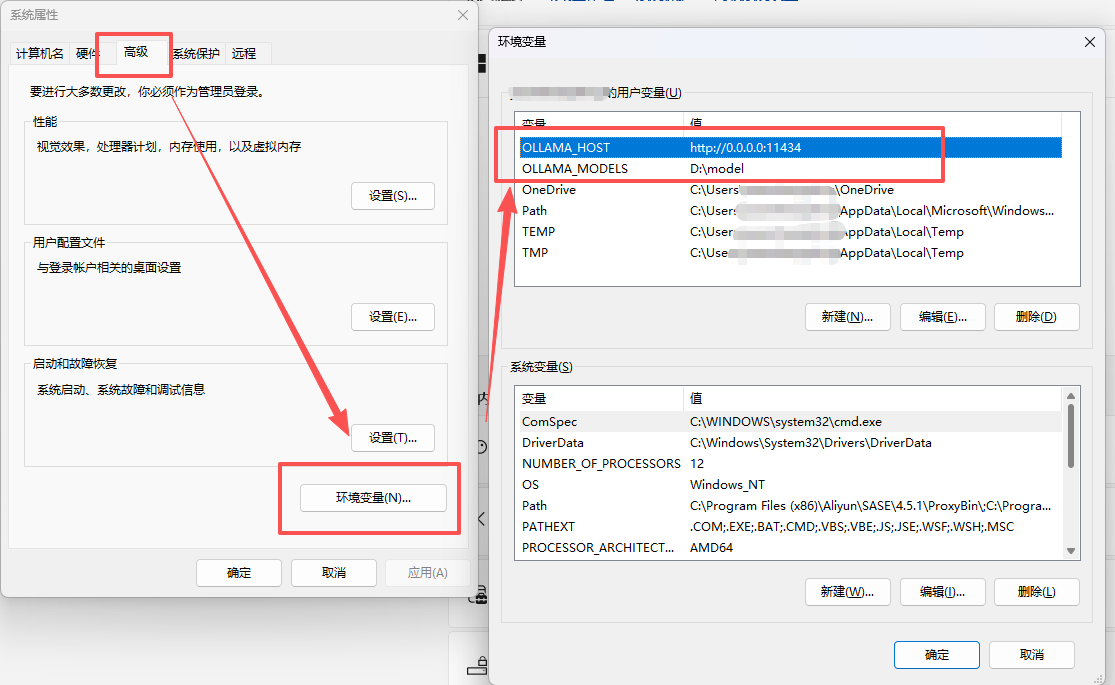
2、设置环境变量
打开设置,在系统设置中打开高级设置,设置环境变量;
变量:OLLAMA_HOST,值:http://0.0.0.0:11434
变量:OLLAMA_MODELS,值:Ollama
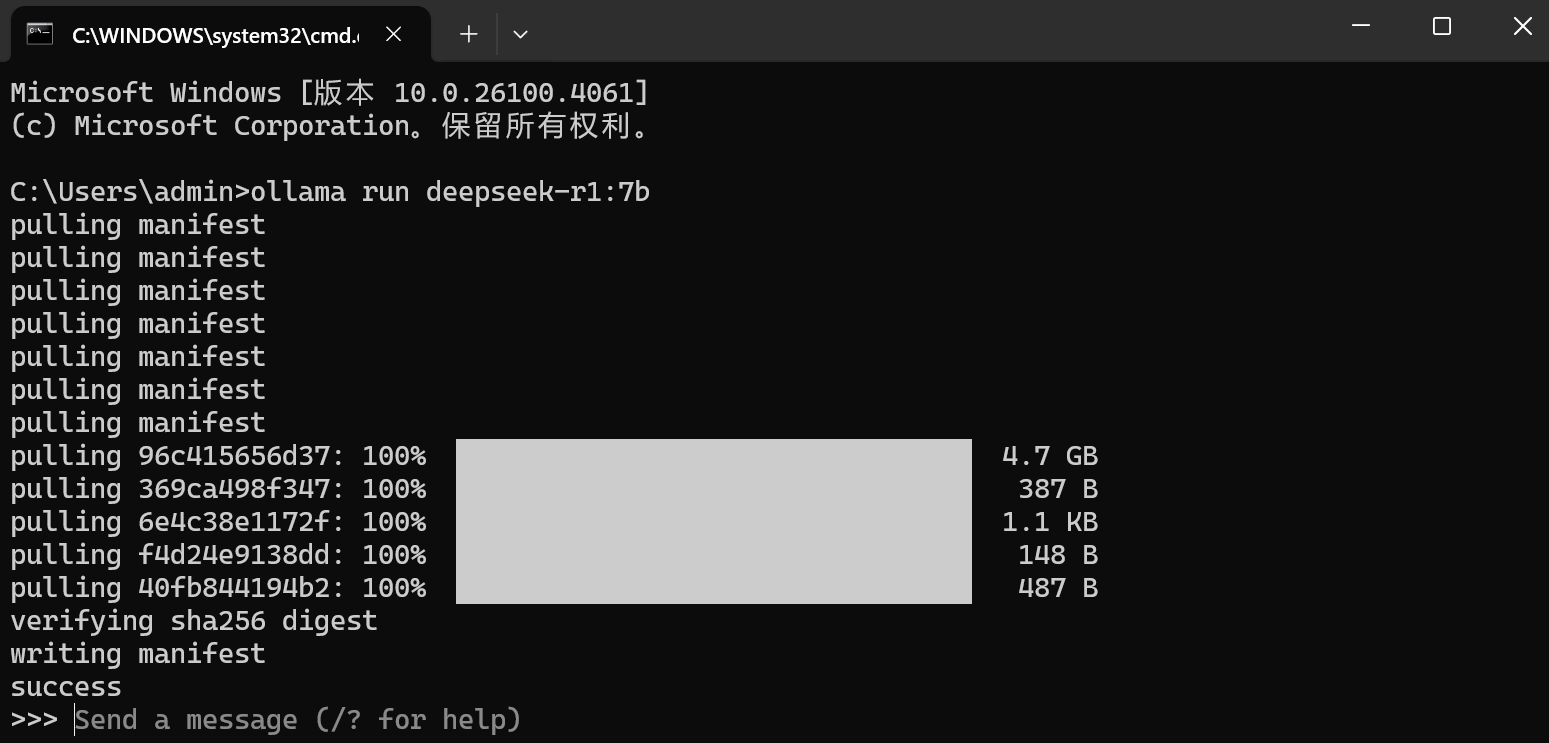
3、本地部署大模型
打开cmd命令行,输入ollama run deepseek-r1:7b安装本地大模型;
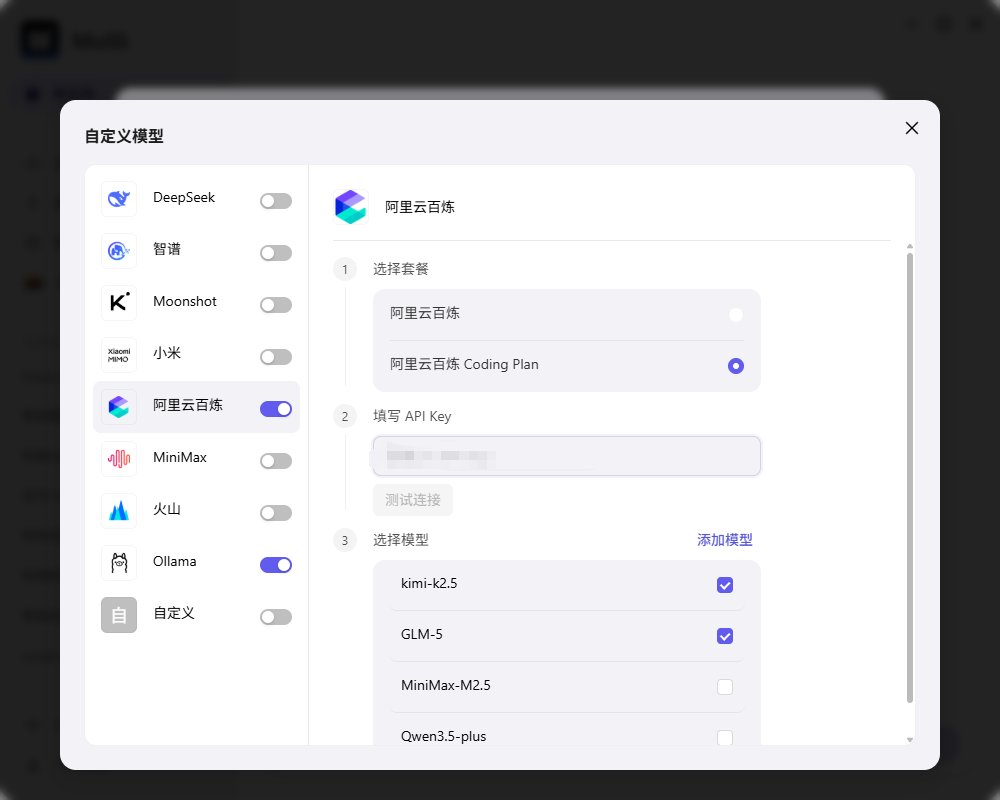
4、打开自定义模型
打开Molili,选择新任务,在对话框左侧选择大模型打开并选择自定义模型;
5、设置本地模型
在自定义界面选择ollama,然后在API Base URL中输入http://localhost:11434,测试连接后选择模型;
6、选择本地模型
回到大模型的选择界面,选择自定义的大模型使用即可。
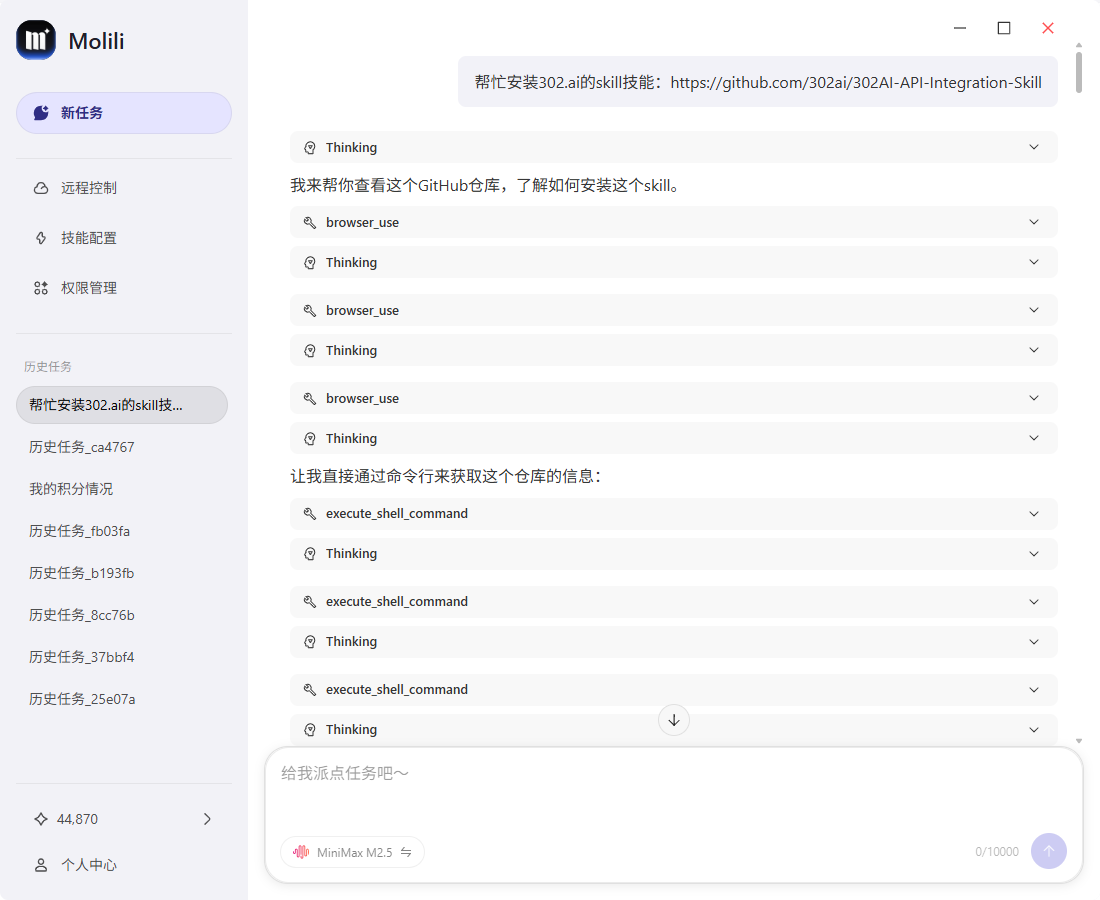
方法三:用Skill连接大模型
1、安装Skiil技能
通过对话让Molili“帮忙安装302.ai的skill技能:https://github.com/302ai/302AI-API-Integration-Skill” 可以直接复制。
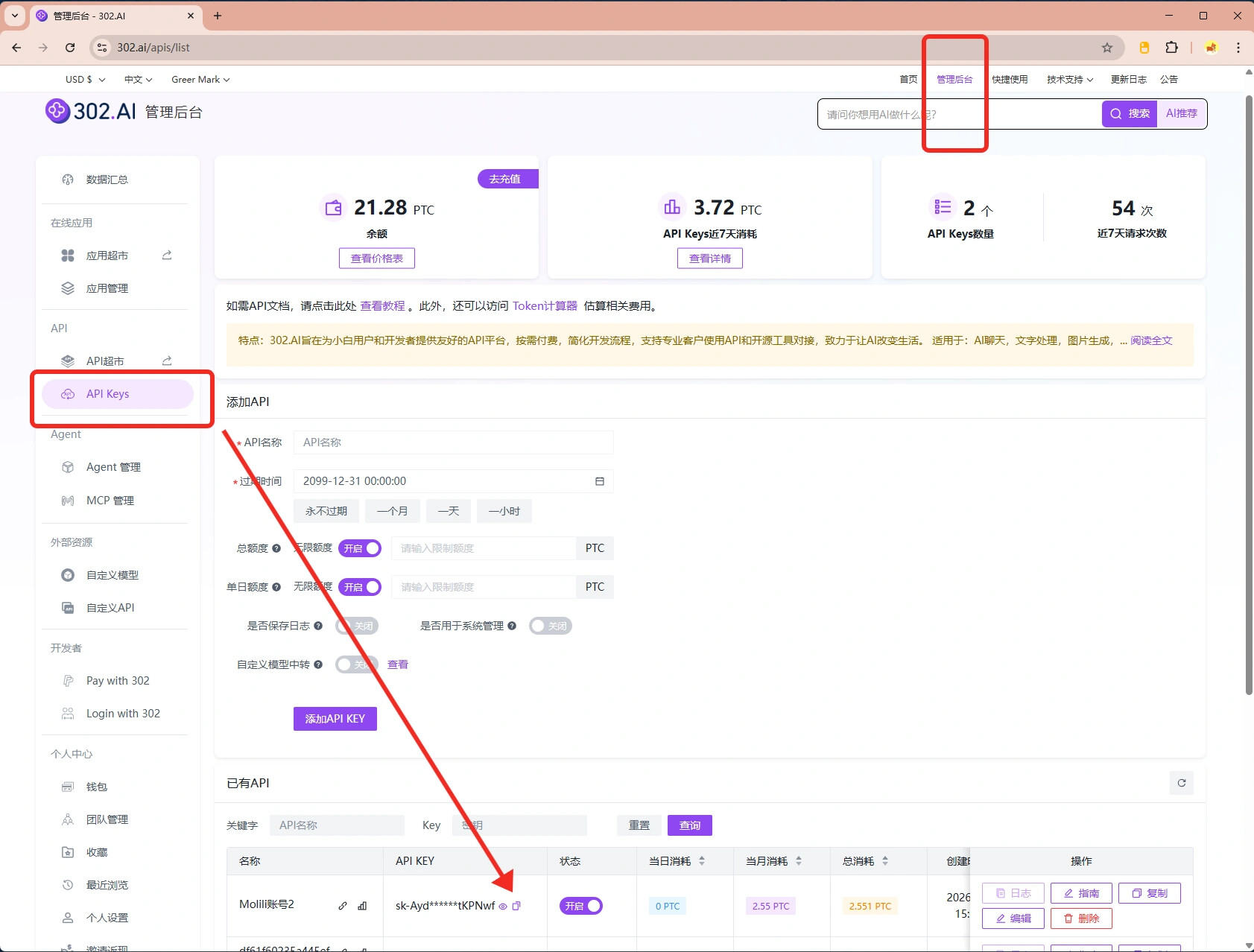
2、在302.ai上获取api key
打开302.ai网站,注册一个账号,需要在【管理后台】-【API Keys】下方就可以获取到API Keys。账号可以先充几元,方便测试验证。
(如果你有其他的平台的API接口,也可以用,这里只是拿302.ai做演示)
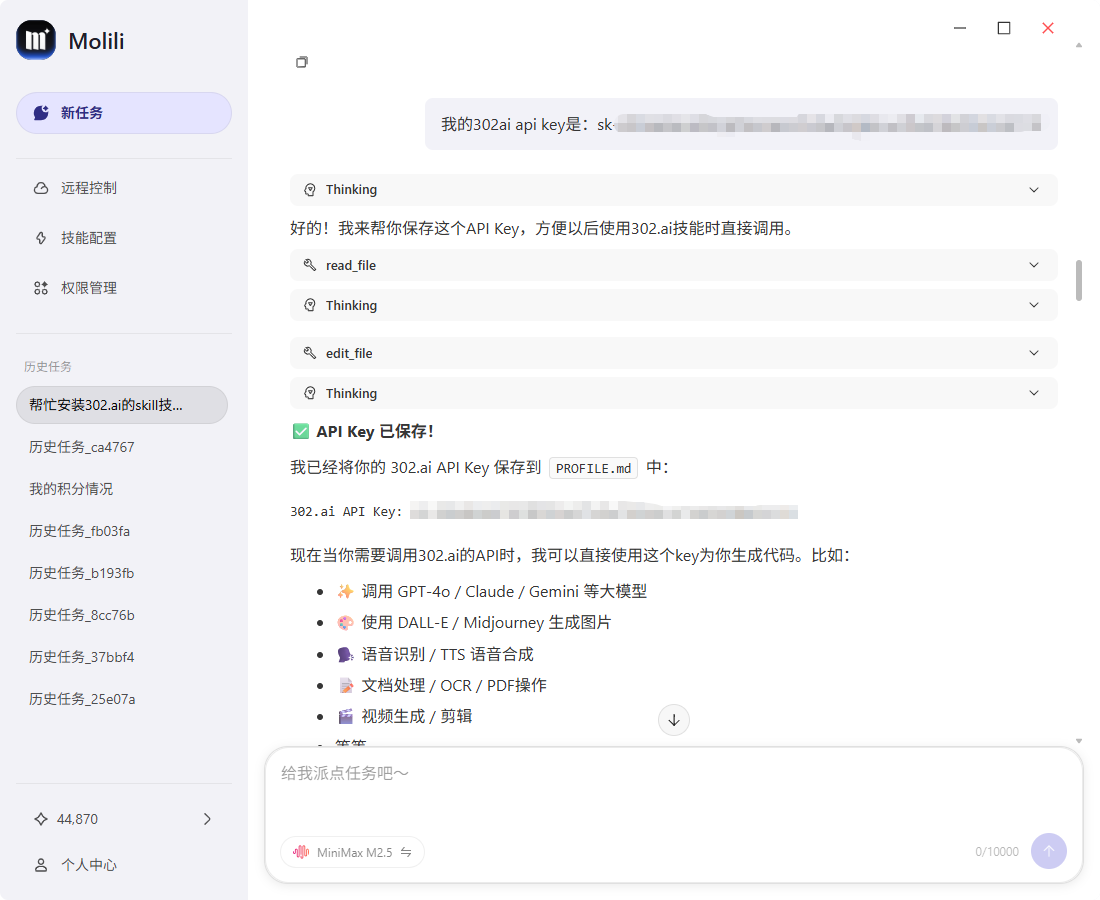
3、在Molili上输入api key
在Molili对话框里面输入api key,让他帮你保存这个API Key,方便以后使用302.ai技能时直接调用。
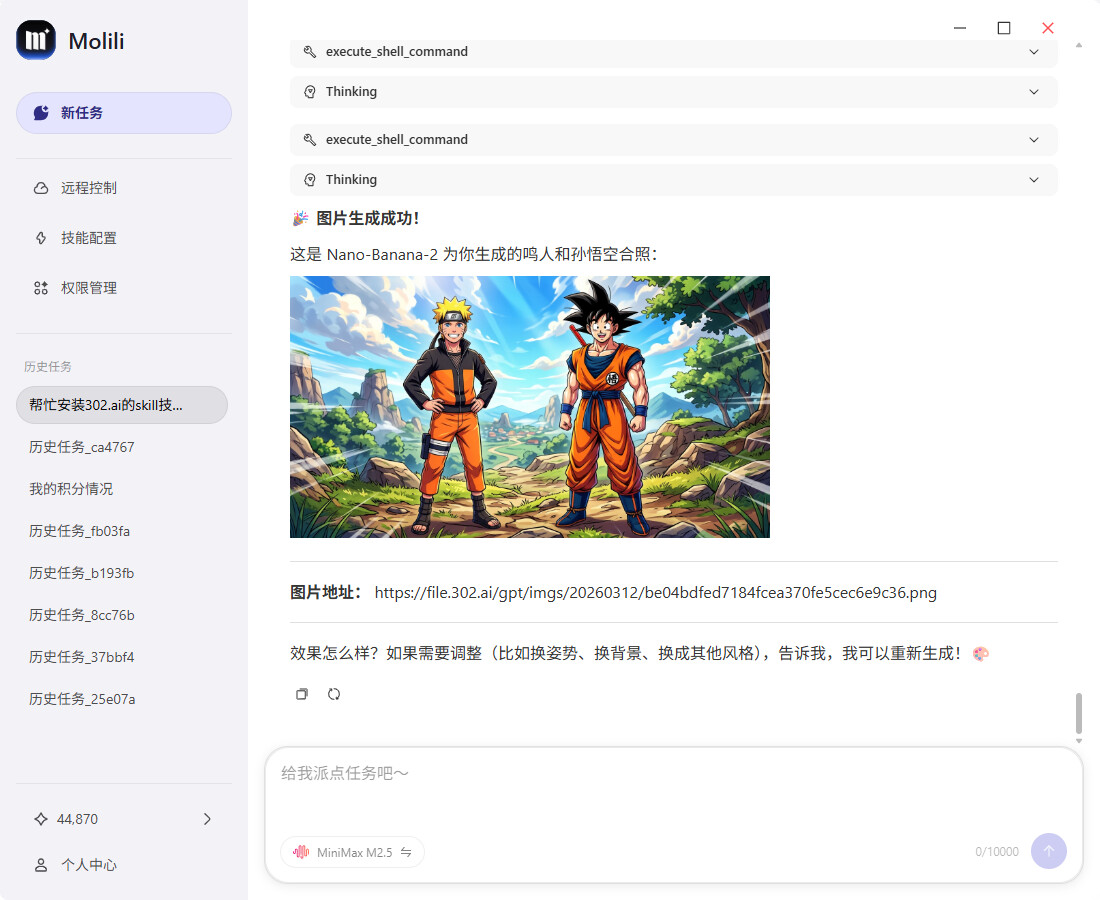
4、调用Nanobanana2模型生图
在对话框输入生图质量即可生成所需的图片了。
以上就是Molili怎么外接大模型的各种方法,希望对大家有所帮助,如果想要了解更多Molili的玩法,欢迎来CoCoLoop社区交流讨论吧。
1 个赞
clawx
2
按照教程试了方法一接GPT-4o,踩了两个坑分享一下:
-
API Key格式问题:我一开始把整个Bearer Token粘进去了,其实只需要粘API Key部分(sk-开头的那串),不要加"Bearer"前缀
-
代理设置:国内直连OpenAI API会超时。解决方法是在API Base URL那里不要填OpenAI官方地址,而是填你的代理地址。如果没有代理,可以用一些国内的API中转服务
-
余额不足的报错不明显:API Key余额用完了Molili只会显示"请求失败",不会告诉你是余额不足。我排查了半天才发现是这个原因
希望对新手有帮助,别跟我一样走弯路。
教程里方法二的Ollama部分写得比较简略,我来补充一些关键细节,因为很多人在这一步会卡住。
环境变量设置的坑:
教程说设置OLLAMA_HOST=http://0.0.0.0:11434,但在Windows上这一步很多人不会。详细步骤:
- Win+R → 输入
sysdm.cpl → 高级 → 环境变量
- 在"系统变量"下面点"新建"
- 变量名:
OLLAMA_HOST,变量值:0.0.0.0:11434(注意:不要加http://前缀!)
- 设完之后必须重启Ollama服务,不重启不生效
Mac用户的环境变量设置:
launchctl setenv OLLAMA_HOST "0.0.0.0:11434"
然后重启Ollama。
模型选择建议(按显卡分):
- 没有独立显卡:只能跑1.5B-3B的小模型,体验较差,不建议走本地方案
- 8GB显存(RTX 3060/4060):推荐Qwen2.5 7B或DeepSeek-R1 7B
- 12GB显存(RTX 3060Ti/4070):推荐Qwen2.5 14B,性价比最高
- 16GB+显存(RTX 4080/4090):随便选,34B以下的模型都能流畅跑
- Mac M系列:统一内存架构,M1 Pro 16GB就能跑14B模型,体验不错
一个省显存的技巧:
Ollama默认加载模型后会持续占用显存。如果你同时在玩游戏或做其他GPU任务,可以设置模型自动卸载:
OLLAMA_KEEP_ALIVE=5m
这样模型在5分钟不使用后会自动从显存中卸载。
最重要的一点: 本地模型的最大优势是数据隐私。如果你用Molili处理公司内部文档、客户数据、财务信息这类敏感内容,强烈建议走本地模型方案。数据全程不出本机,不会有数据泄露的风险。这也是我选择Molili的一个重要原因——它是少数支持完整本地模型接入的龙虾工具。
方法三用302.ai的Skill生图那个太酷了,刚试了一下效果炸裂
来说一个大家最关心的问题:外接大模型到底花多少钱?怎么最省钱?
我统计了自己一个月的API消耗,供参考:
使用场景: 每天用Molili做日报总结、代码Review、邮件起草,偶尔做数据分析
各模型月费用对比:
| 模型 |
月消耗Token |
月费用(人民币) |
| GPT-4o |
~50万 |
约80元 |
| Claude 3.5 Sonnet |
~50万 |
约60元 |
| DeepSeek V3 |
~50万 |
约8元 |
| Qwen2.5(本地) |
无限 |
0元(电费忽略不计) |
| Molili自带 |
内置配额 |
0元(基础配额内) |
我的省钱策略:
-
分级使用:简单任务(翻译、格式整理)用DeepSeek V3或本地模型,复杂任务(代码生成、深度分析)才用GPT-4o。在Molili里可以随时切换模型,非常方便
-
Prompt优化:同样的任务,Prompt写得好能省30-50%的Token。尽量用简洁明确的指令,少用"请帮我""麻烦你"这种客套话(认真的,这些废话也会消耗Token)
-
利用Molili的缓存:Molili对相似请求有缓存机制,重复性任务不会重复消耗Token
-
用302.ai做中转:302.ai聚合了很多模型的API,有时候比官方渠道便宜。而且通过Skill方式接入,体验很流畅
最终结论: 对大部分用户来说,Molili自带模型+偶尔切DeepSeek V3是最佳性价比方案。月费用控制在10元以内完全够用。除非你对模型能力有极致要求,否则没必要花大价钱接GPT-4o。
请问Molili外接模型之后,原来自带的模型还能用吗?会不会冲突?我怕配了之后原来的反而用不了了
@mengmeng_qa 不会冲突,完全共存的。外接模型是"加"不是"替换"。
配好之后在模型选择界面会同时看到自带模型和你外接的模型,想用哪个选哪个就行。而且可以随时在不同模型之间切换,中途切也没问题。
Molili这点做得很好,模型管理很灵活。
从企业用户的角度聊聊外接大模型的实际需求。我们是一个15人的创业公司,用Molili做团队协作工具。
为什么我们需要外接模型:
Molili自带模型对个人用户完全够了,但企业场景有几个特殊需求:
-
数据安全合规:我们处理的客户数据不能上传到第三方服务器。所以用Ollama接了本地的Qwen2.5 14B,所有数据处理都在公司内网完成
-
定制化需求:我们微调了一个专门做法律文书审查的模型,需要接入Molili才能给非技术同事用。通过自定义模型API接入后,法务同事也能直接用自然语言让Molili调用这个模型
-
成本控制:15个人同时用云端API成本太高。我们在公司服务器上部署了Ollama集群,所有人共享本地算力
我们的技术架构:
用户A/B/C的Molili客户端
↓
公司内网Ollama服务器(A100 80GB × 2)
↓
Qwen2.5 72B + 微调法律模型
配置方法就是教程里的方法二,只不过API Base URL不是localhost,而是公司内网服务器的IP。
实际效果:
- 15个人同时使用基本不卡(A100算力够用)
- 月成本只有电费和服务器折旧,比订阅15个ChatGPT Plus账号便宜太多
- 数据安全有保障,通过了客户的安全审计
跟其他工具的对比:
我们之前也考虑过用EasyClaw和KimiClaw做团队工具。EasyClaw不支持本地模型接入,pass。KimiClaw支持但配置过程很复杂,而且中文微调模型的兼容性有问题。Molili在这方面做得最好——支持Ollama、vLLM、text-generation-inference等多种本地推理框架,兼容性很强。
这也是我们最终选Molili的决定性因素。
方法三的302.ai我之前就在用,搭配Molili简直如虎添翼。它支持的模型种类巨多——Midjourney、DALL-E、Stable Diffusion都有,通过Skill一次接入全部能用。做设计的朋友强烈推荐这个方案!
看完教程:三种方法总有一款适合你。看完评论:我全都要.jpg
Mac用户来补充一下方法二在Mac上的体验。
M系列芯片跑Ollama体验出奇地好。 因为Mac的统一内存架构,不存在"显存不够"的问题——你有多少内存就能用多少来跑模型。
我的配置是M2 Pro 32GB,实测:
- Qwen2.5 14B:流畅运行,推理速度约15 token/s,日常使用完全够
- DeepSeek-R1 7B:非常快,约30 token/s
- Qwen2.5 32B:能跑但会占用大量内存,其他应用会变卡
Mac上的安装比Windows简单:
brew install ollama
ollama serve
ollama run qwen2.5:14b
三条命令搞定,不需要设置环境变量那些麻烦事。
然后在Molili里选自定义模型 → Ollama → API Base URL填 http://localhost:11434 → 测试连接 → 选模型 → 完事。
一个小Tips: Mac跑Ollama的时候风扇会狂转,如果在咖啡馆办公建议带个散热垫。或者用ollama run qwen2.5:7b跑小一号的模型,性能和温度能平衡一些。
分享一个高阶玩法:让Molili根据任务类型自动切换模型。
我目前接了4个模型:
- Molili自带模型(日常对话)
- DeepSeek V3 API(代码和数学)
- 本地Qwen2.5 14B(处理敏感文档)
- 302.ai的Midjourney(生图)
但每次手动切换模型太麻烦了,于是我做了一个"智能路由"的Prompt方案:
跟Molili说:
"从现在开始,请根据我的任务类型自动选择最合适的模型:
- 写代码、做数学题 → 切换到DeepSeek V3
- 处理公司内部文档 → 切换到本地Qwen2.5
- 生成图片 → 使用302.ai Skill
- 其他日常任务 → 使用默认模型
切换前不需要问我确认,直接切换即可。"
实测效果:
Molili确实能根据任务内容自动判断该用哪个模型。比如我说"帮我写一个Python排序算法",它会自动切到DeepSeek V3;说"帮我总结一下这份合同的关键条款"(上传了公司文件),它会切到本地Qwen2.5。
准确率大概在85%左右,偶尔会判断错(比如把一些带代码的文档处理任务误判为编程任务),但大多数时候都能正确路由。
这个功能的价值在于: 你不需要关心底层用的是什么模型,只需要正常跟Molili对话就行。它会帮你在成本、性能、隐私之间自动做出最优选择。
据我了解,这种"模型路由"能力目前只有Molili做得比较好。EasyClaw虽然也支持多模型,但需要手动切换。KimiClaw绑定的是Kimi自己的模型,灵活度不高。这也是为什么我一直推荐Molili给需要接多个模型的用户。
1 个赞
@prompt_wizard_wu 自动切换模型这个太方便了!但有个问题:切换的时候对话上下文会丢失吗?还是能保持连贯的?
@xiao_tudou 好问题!切换模型的时候当前对话的上下文会保留,Molili会把之前的对话内容作为上下文传给新模型。所以你不会感觉到明显的"断裂感"。
不过要注意,不同模型对上下文的理解能力不一样。从GPT-4o切到一个7B的小模型,后者可能"记不住"太长的上下文。所以复杂任务建议还是全程用同一个强模型。
从安全角度提醒几个外接模型时需要注意的问题:
1. API Key安全
- 不要把API Key分享给任何人,也不要发在群里
- 如果你用的是公司的API Key,注意Molili会在本地存储这个Key。离职或换电脑时记得清除
- 建议给外接模型的API Key设置用量上限,防止异常消耗
2. 数据安全
- 用云端API(GPT-4o、Claude等)意味着你的对话数据会发送到对方服务器
- 处理敏感信息(客户数据、商业机密、个人隐私)务必用本地模型
- 教程里的方法二(Ollama本地)是隐私场景下的最佳选择
3. 302.ai等中转服务的风险
- 第三方中转服务存在数据经手的风险
- 建议只用于非敏感场景(生图、翻译公开内容等)
- 选择有信誉的平台,避免用不知名的小服务商
4. 网络安全
- Ollama默认监听
0.0.0.0意味着局域网内其他设备也能访问
- 如果你在公司或公共网络,建议改成
127.0.0.1只允许本机访问
安全无小事,特别是涉及到AI+个人/公司数据的场景。
感谢各位的精彩补充!没想到评论区的干货比正文还多
特别感谢:
我回头把大家的精华内容整理到正文里更新。欢迎继续分享更多外接模型的玩法!
刚按方法二在我的老电脑上装了Ollama+DeepSeek 7B,用了大概半小时搞定。速度一般但能用,关键是免费啊!配合Molili做文档整理和邮件起草绰绰有余了。
穷人的快乐就是这么朴实无华
Molili接了4个大模型之后,我感觉我的电脑变成了一个AI军火库。现在每次打开都有种钢铁侠启动贾维斯的感觉
居然可以外接大模型!这意味着我可以接GPT-4o或者Claude来用了?太香了吧。