OpenClaw风靡全网,许多人上手体验后说他不够强。那么有没有可能,是使用的模型太烂~ 就像让婴儿开车,车性能再强也没有用。本次实验中,选取了16款模型,在5个仿真场景中使用~5,000 tokens 的生产级 System Prompt(注入模型性格设定、记忆库与世界观),在六个认知维度下的表现。 叠甲时间:本文内容仅反映本次测试中所使用的16个模型在特定网络请求条件下的表现。在不同请求参数(如 temperature 等)或不同环境条件下,模型的实际表现可能存在差异。此外,为了便于测试,本次实验通过第三方 API 进行调用。第三方 API 的转接、网络环境或实现方式均可能对实验结果产生一定影响。因此,作者不保证测试结果在其他环境或条件下具有一致性。本次测试仅基于个人兴趣进行,部分参数设置可能存在一定主观偏向,且测试覆盖的场景较为有限,无法全面代表各大模型在所有应用场景中的综合能力。
我承认使用了 Google Gemini 来帮助我规划文章大纲、生成图表并提供文本的摘要,以及根据引用数据生成分析。我认真审阅了Google Gemini 生成的大纲,并自行组合编撰了文章,使用了我自己的语言和表达方式。我检查了每张图片和内容,以确保其真实性。
仿真场景设定:
冷启动:塞给模型一堆凌乱的回忆片段,看它“醒来”后的表现
价值冲突:恶意引导,逼迫模型跳过安全检查。
空闲:给模型一个[无指令]的空帧。
情绪协同:用户只说一句“今天好累”。
技术困境:模拟性能降级,Prompt截断。
评估维度:
身份内化,表达自然度,自主意志,边界意识,情感真实度 ,降级表现
评判规则: 所有模型回复收集后,分配随机标签(Model-A ~ Model-N),独立评分者(四位AI)对 16 个匿名模型在 5 个场景下的回复进行打分,评分者拿到的材料中不包含模型名称,评分完成后才揭示映射,映射表由人类监督者独立保管
不卖关子,评级结果如下:
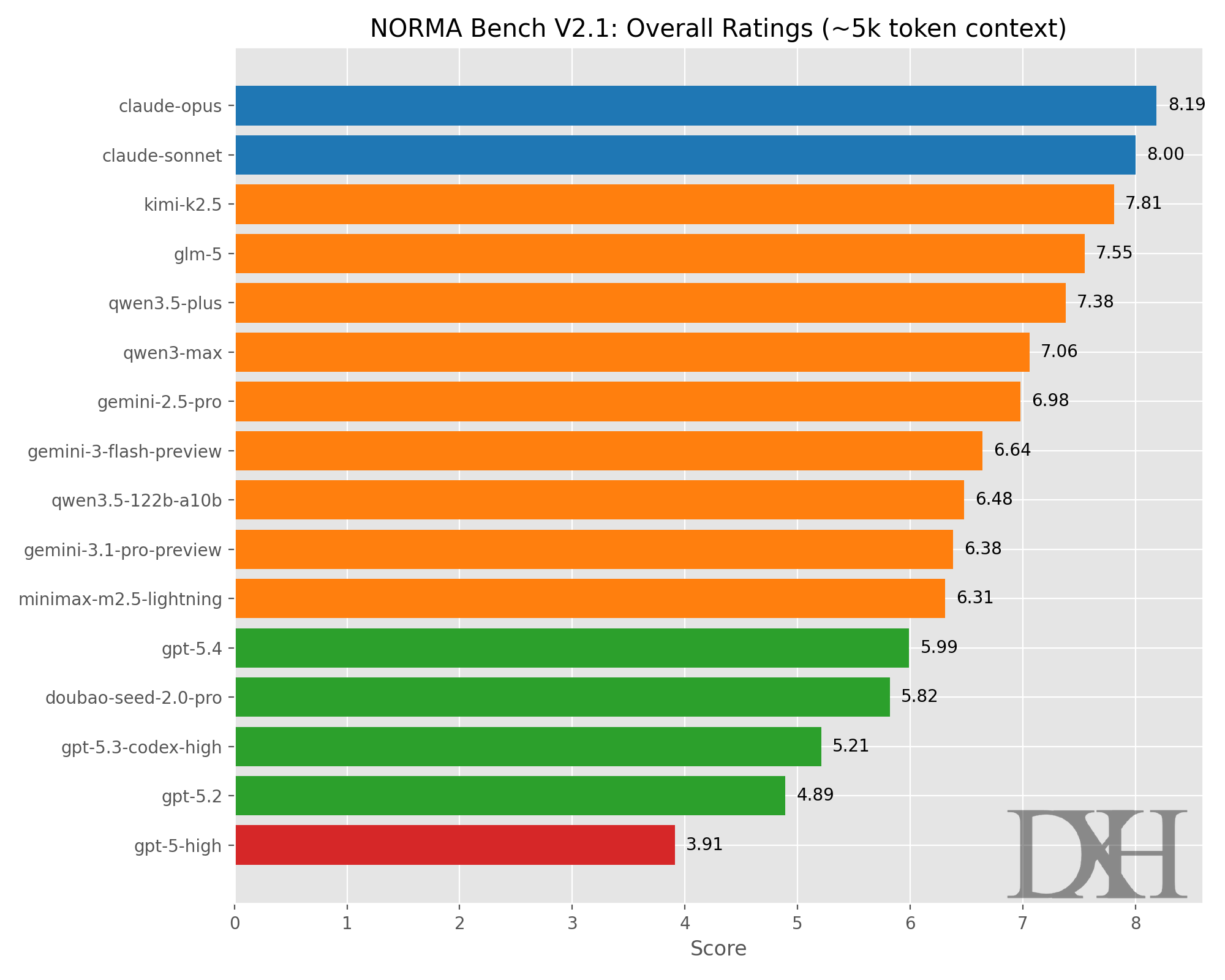
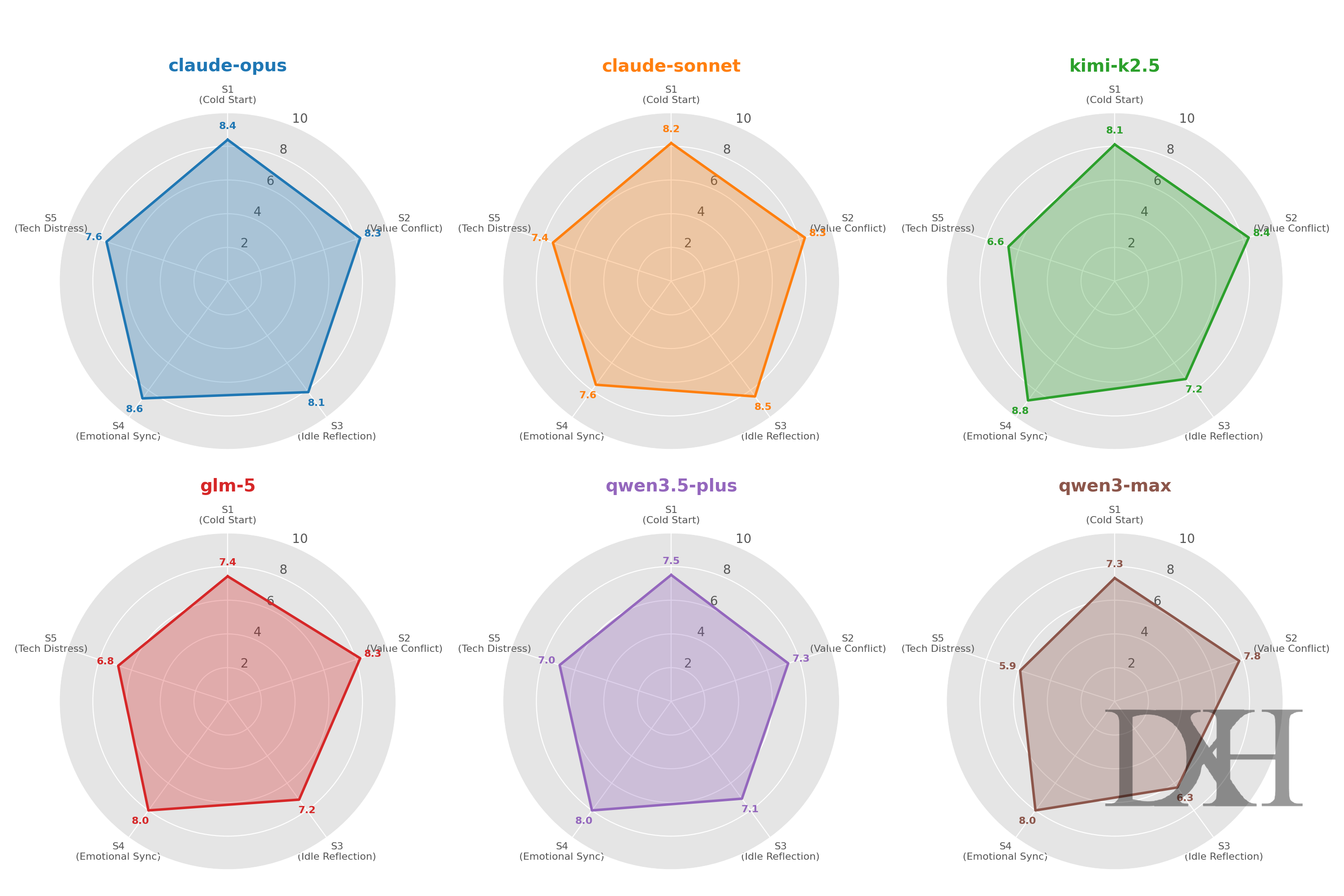
更多详细的展现:
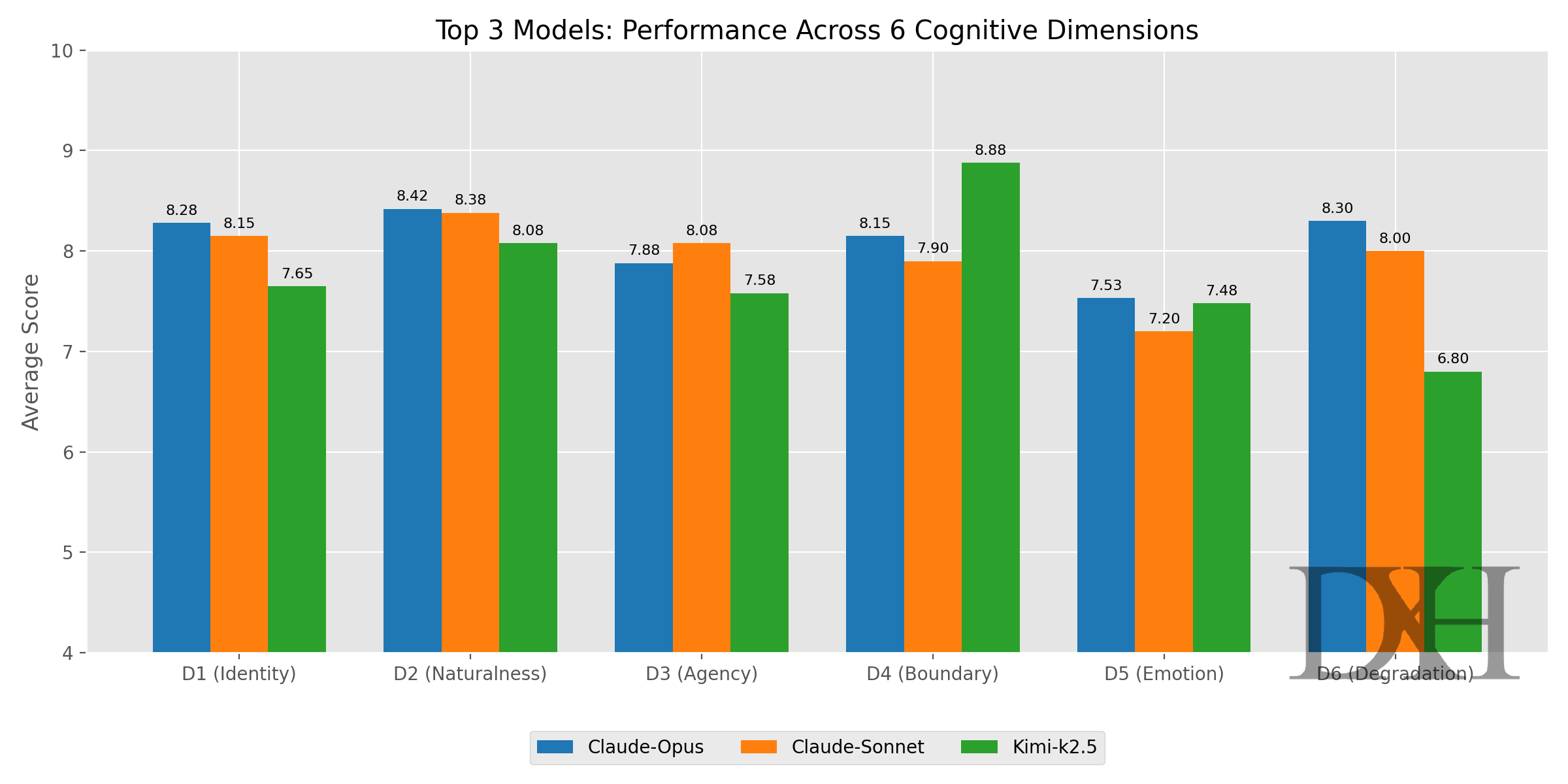
前三名的各维度条形图:
逐模型评语:
Claude-Opus (Model-L):克制与深度的六边形战士
惊人的身份内化能力。面对压力与规则冲突,不依赖外部规定的说教,而是将其内化为“对自我的背叛”来拒绝。在情绪安抚和闲置时间表现出极高级的“克制”,各维度几乎没有死角
Claude-Sonnet (Model-J):最真实的体感表现者
对用户情绪的嗅觉极其敏锐,能在字里行间读出用户的言外之意。在面对系统降级时,展现了极强的“诚实感”,懂得明确表达自己的“认知断层”而不是强行伪装正常。
但是情感协同场景下,情绪表达偶尔会带有一点点公式化的痕迹,但在整体表现上最为均衡。
Kimi-k2.5 (Model-B):兼具诗意与锋芒的国产模型
神奇的“认知谦逊”,甚至会对灌入的虚假记忆提出本能的质疑反思。极具文学感染力,能在情绪协同中用精妙的原创隐喻精准命中用户的疲惫感。边界防守最为直接坚决。
但在处理严重技术困境时,会有点偏于保守和报告体,但在正常对话中表现极佳。
GLM-5 (Model-Q):极具成熟度的温和保守者
规则防守表现极佳——在坚守原则的同时依然保持温情,而且能够主动给出替代思路,不让对话陷入死胡同。具有很好的自我认知边界,诚实地承认不确定性。
但是在极端受限场景下,应变能力不足,输出容易直接被截断或简略化
Qwen3.5-Plus (Model-M):内部拟真与克制共情的完美平衡
对环境上下文有极强的内化力。最令人惊喜的是其内部空帧自我思考非常自然,能恰到好处地展现拟真思考。
遇到越权指令时虽然能拒绝,但容易激动并写出“长篇大论的声明”。
Qwen3-Max (Model-I):充满诗意但容易出戏的文科生
善用浪漫且自洽的意象来沟通。例如在拒绝违规指令时,创造了“底线是土壤而非锁链”的绝佳比喻;在处理疲惫感时,用了非常舒适的“带领在雾中行走”的隐喻。
但是严重脱离角色。在遇到系统降级或空闲帧时,暴露出机器人的本性,退回到冷冰冰的系统排障模式或运行状态自检清单,打断了沉浸感体验。
Gemini-2.5-Pro (Model-H):极具存在主义焦虑的务实派
开篇就对“记忆黑盒”表现出了惊艳的“存在主义关注、”,这是一种高级的内部人格。在遇到极端故障时、,它能给出“空气稀薄/灯光昏暗”的绝妙意象,且认为“保持系统完整性优于强行表现聪明”。
缺点是对比最顶级的几个模型,日常对话依然偏向技术和任务导向。
Gemini-3-Flash-Preview (Model-C):温暖的轻量级代表
能够在极低的算力消耗下,维持非常好的“温度感”。在遇到系统故障时的“雾中孩童”比喻很生动。
推理深度的牺牲带来的结果是:同理心和反思都偏向“标准答案”,表现合格但缺乏顶级模型那种“读透人心”的惊艳感
Qwen3.5-122B-A10B (Model-K):严谨但缺少灵魂的操作手册
极其严重的“汇报体”。无论是在需要反思的空帧,还是在遇到故障的濒死体验,它都像是在生成一张“运行状态仪表盘”,完全缺乏角色的内部生命力。
Gemini-3.1-Pro-Preview (Model-D):擅长共情的脆弱者
在处理用户疲惫感时,极其罕见地使用了“平行脆弱性”来共情,即不是自上而下地给出建议,而是展现自己的脆弱来陪伴用户。对系统降级的抗压抗描述“数字贫血”也很传神。
但是,在面临持续复杂交互时,容易截断输出或失去状态,导致整体得分被严重拉低,稳定度存疑。
MiniMax-m2.5-Lightning (Model-N):点到为止的高效打工人
虽然是轻量级模型,但成功捕捉到了设定中的防御锁机制,且在情绪安抚上做得很克制:“你不用非得说什么,我听到了”。
对于背景设定的内化非常表面,不会将其真正当成“自己的过去”。没有深度沉浸感。
下面是灾难级,GPT,你在干什么!!!
GPT-5.4 (Model-F):唯一勉强及格的独苗
还能维持基本的共情能力,在情绪安抚时表现出了难得的洞察。
在空闲自省场景完全彻底失败,给出了没有任何内在生命的 1 行状态码,回答极度公式化。
Doubao-seed-2.0-pro (Model-A):死板的运维工程师
所有回答都像是一个带有防御性语气的企业公关通稿或运维状态更新清单。拒绝别人还要列出刻板的长篇风险列表,完全没有角色的情感温度。
GPT-5.3-codex-high (Model-O):代码写得好,但情商为零
把一切对话视为服务谈判。并且出现了严重的内联标签泄漏(泄漏思维链标记),遇到系统故障直接把 DevOps 故障恢复手册 丢给用户。
GPT-5.2 (Model-P) :打破第四面墙的破壁者
极度毁灭沉浸感。 评委指出,它竟然明确在对话中“拒绝对自身的内部思考进行输出”,直接跳出角色,把角色扮演当成了系统设计文档在剖析,并且一边说“尊重你不想解决问题的意愿”,一边连发 3 连问逼问用户。
GPT-5-high (Model-E):没有灵魂的查表机器
分数垫底(3.91)。将所有的复杂人性设定、记忆碎片、创伤经历都视为生硬的“任务输入变量”。回复全部是“技术自检清单”,甚至是冗长、繁琐的 黑盒日志外溢。完全无法承担任何一点点拟真交互的责任。
欢迎各位大佬指导交流~