物理AI系统得先搞懂现实世界,才能在里头动起来。机器人、自动驾驶车、智能空间这些,都需要明白周围在发生什么,预测下一步可能咋样,然后针对具体环境、身体形态和任务生成行动。
NVIDIA Cosmos 3是个挺前沿的物理AI基础模型,它把物理推理、世界生成和行动生成这些能力,都塞进一个开放的模型里了。
NVIDIA这次把Cosmos 3模型、训练脚本、部署工具还有数据集都开源了,想让物理AI开发更开放、更好复现。这篇帖子就说点Cosmos 3的基础,重点提一下技术报告里的关键概念,给技术流程指个路,也说说搞机器人操作系统、自动驾驶汽车和仓库监控方案的团队该怎么上手。

图 1. Cosmos 3 为自动驾驶领域生成的视频片段

图 2. 使用 Cosmos 3 为仓库安全数据生成的视频。
这次发布的主要东西有:
- NVIDIA Cosmos 3 Nano 和 NVIDIA Cosmos 3 Super 的模型检查点,在Hugging Face上能下,代码在GitHub。
- 给机器人、自动驾驶这些物理AI应用用的开放数据集。
- 用来把Cosmos 3适配到你那个领域的开放后训练脚本。
- Cosmos NIM微服务,方便在NVIDIA GPU上做优化部署。
Cosmos 3有啥新东西
以前的Cosmos版本,世界生成、物理理解、可控场景生成这些是拆到不同模型和流程里的。这次发布用一个混合变换器架构,把能力统一了。这架构主要靠两个塔:
- 推理塔:一个视觉语言模型,负责理解图像、视频、文字这些多模态输入。用它来解读运动、物体交互还有其他物理上下文。算是生成开始前,理解世界的“大脑”。
- 生成塔:负责生成未来的观察序列和行动序列。它用基于扩散的过程,生成有物理感知的视频和行动输出,这些输出都受推理塔的理解结果影响。推理塔可以单独用,但生成的时候,两个塔总是一起干活来引导生成。
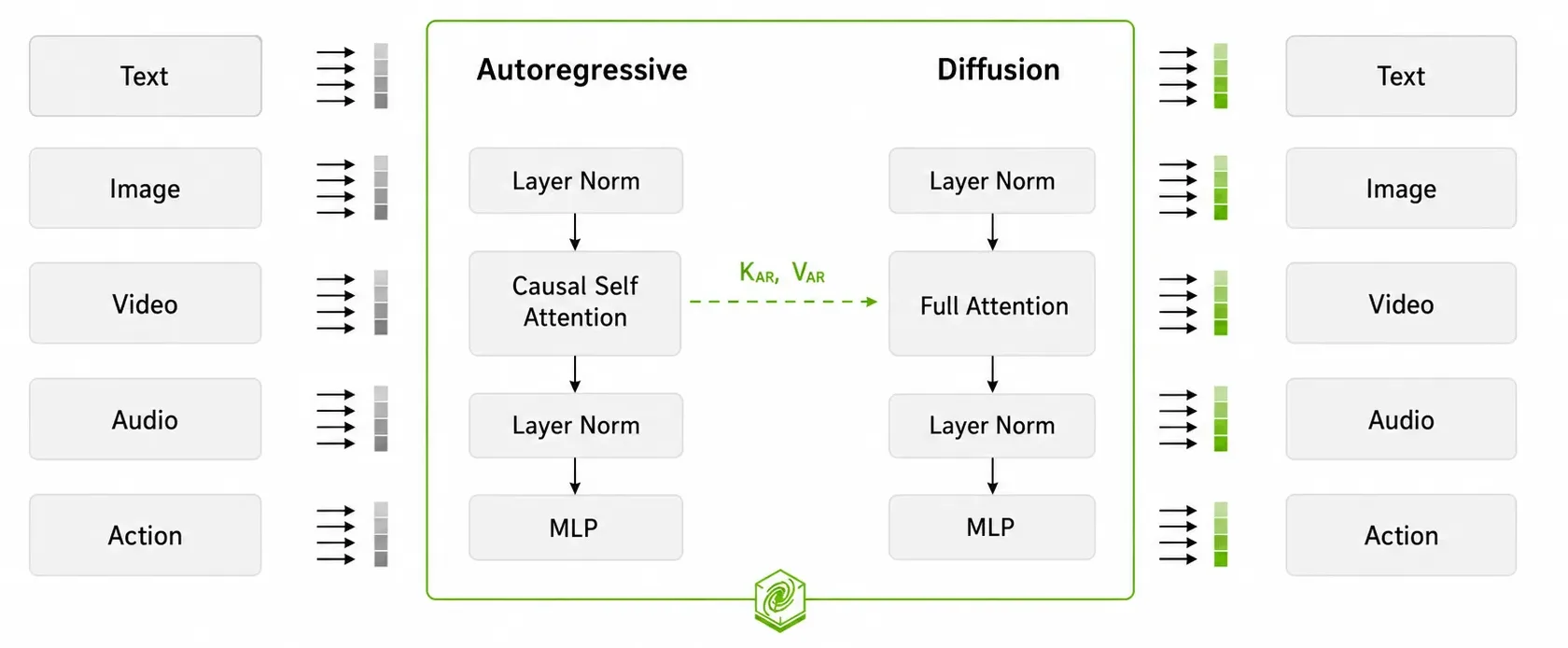
图 3. Cosmos 3 架构
这么搞,一个模型就能干推理和生成,不用再费劲协调多个模型和推理管道了。
选哪个型号合适
现在有两个Cosmos 3模型:
- Cosmos 3 Nano:紧凑版,160亿参数,为高效推理优化过。设计用在像NVIDIA RTX PRO 6000 GPU这种工作站级设备上,适合实时机器人推理和物理AI应用。
- Cosmos 3 Super:640亿参数,追求最高质量和能力。基准测试分数最高,目标是在NVIDIA Hopper和NVIDIA Blackwell GPU上做数据中心部署,适合大规模合成数据生成和高级物理推理这种重活。
支持哪些输入输出
Cosmos 3通过统一架构支持下面这些输入输出模态:
输入输出应用
文本 图像 物理上合理的图像生成
文本 | 视频 视频 用于罕见边缘情况视频数据生成的世界模型
文本 | 图像 视频 用于预测的世界模型
文本 | 图像 | 视频 文本 用于推理的 VLM
行动 | 视频 | 文本 视频 以行动为条件的世界模型
视频 | 文本 视频 | 行动 世界行动模型、视频行动模型、视觉语言行动模型、用于机器人学习的策略模型
表 1. Cosmos 3 为不同应用支持的输入和输出模态
给物理AI用的开放数据集
随着Cosmos 3发布,NVIDIA在Hugging Face上开源了六个合成数据生成数据集。这些数据集覆盖机器人、物理模拟、空间推理、人体运动、驾驶和仓库环境,可以用来给Cosmos 3或其他模型做后训练:
物理AI世界模型合成数据集包括:
- 具身机器人场景
- 物理交互场景
- 空间推理
- 数字人场景
- 自动驾驶场景
- 仓库操作场景

图 4. 来自具身机器人场景数据集的操作示例
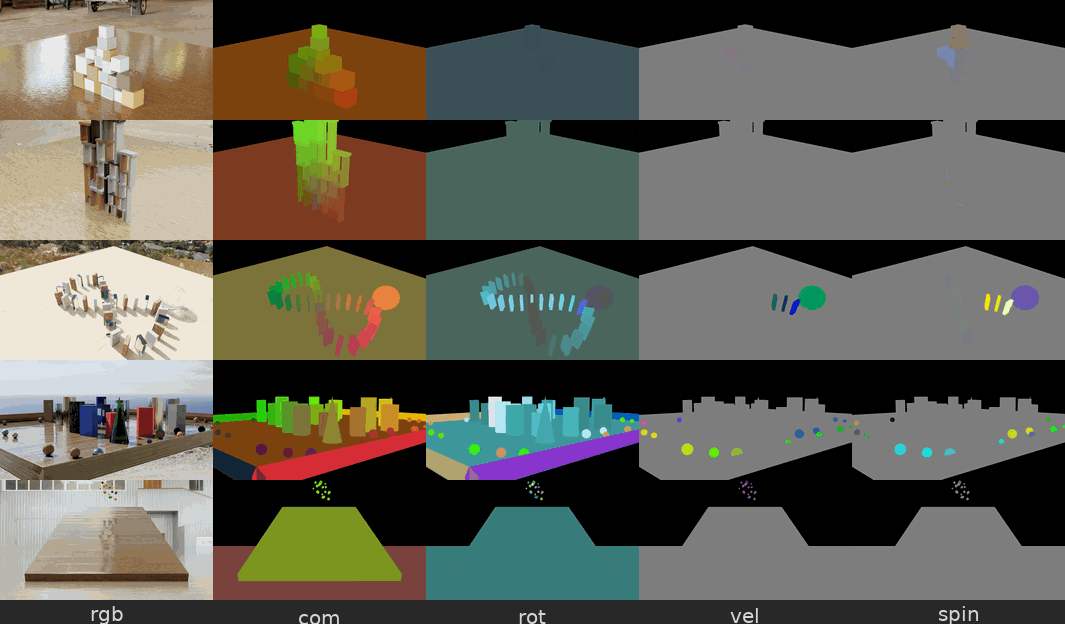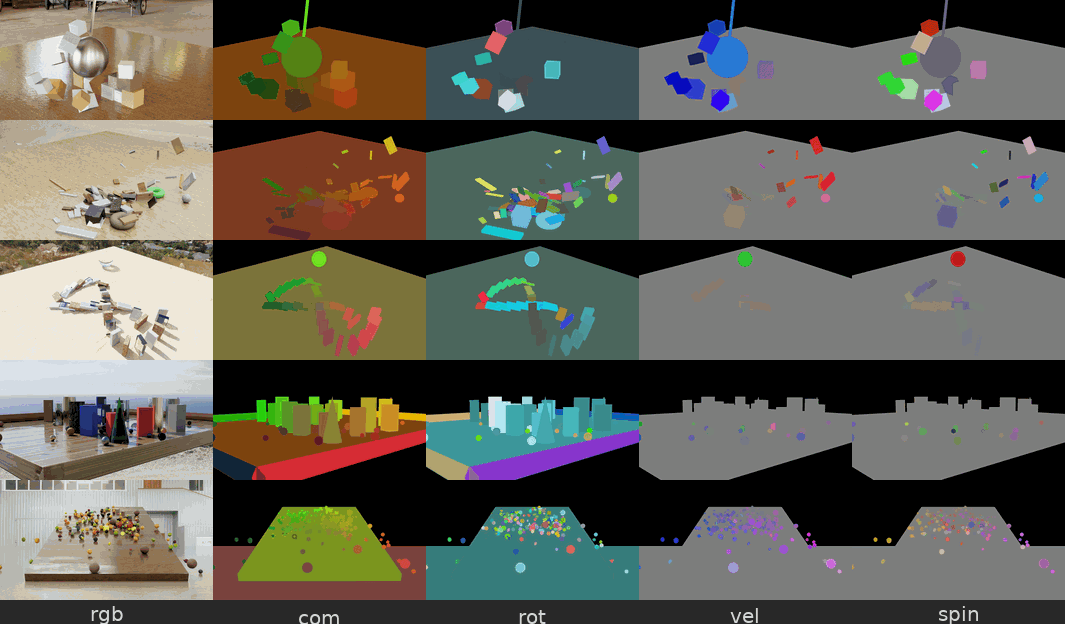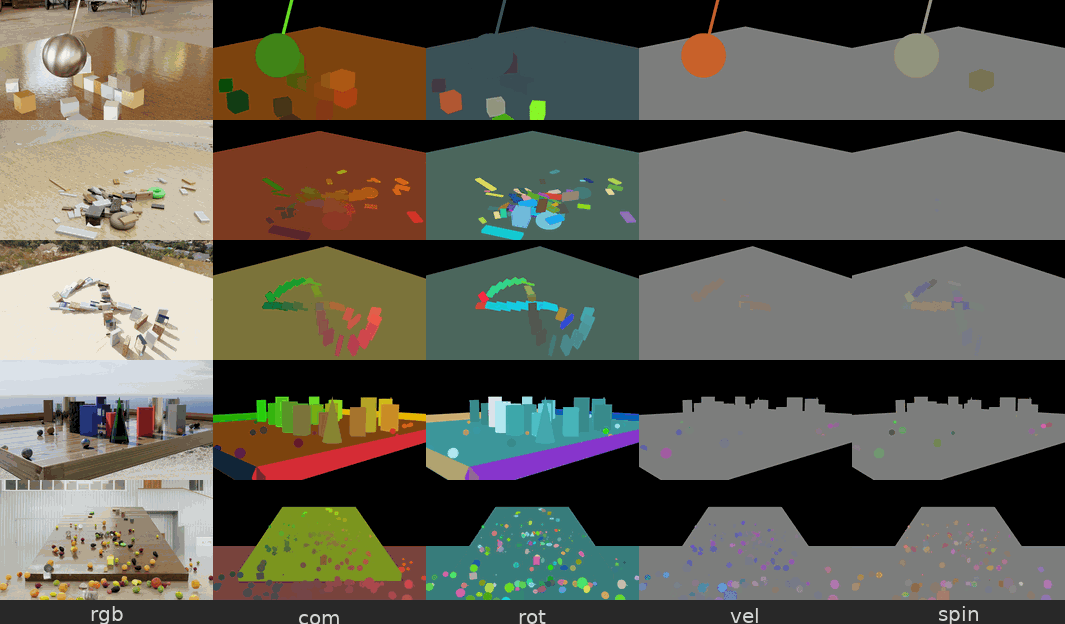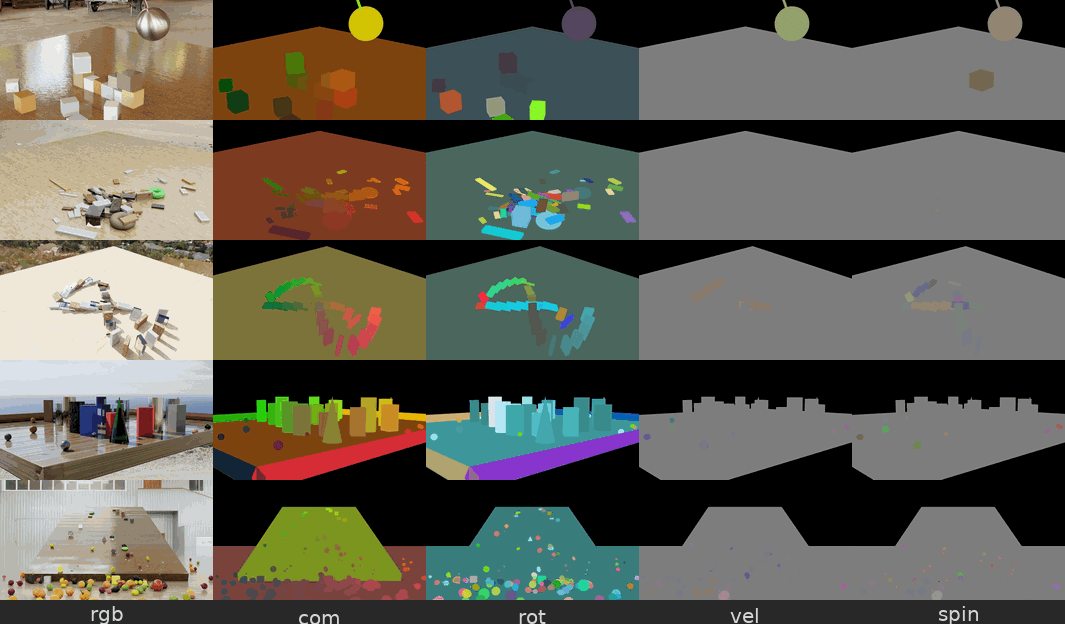
图 5. 来自物理交互场景数据集的示例

图 6. 来自空间推理数据集的示例

图 7. 来自数字人场景数据集的示例

图 8. 来自自动驾驶场景数据集的示例

图 9. 来自仓库操作场景数据集的示例
NVIDIA Cosmos人工评估基准
NVIDIA Cosmos人工评估框架是用来评估Cosmos 3生成器在代表性领域任务上的质量的。
现在那些顶级视频生成模型把自动化排行榜都快刷满了,不同版本之间分数差得又小,比不出啥名堂。HUE框架把评估从主观打分转向客观事实验证,这样顶级模型之间也能做细粒度比较。结果就是一个更可靠的质量信号,既能快速迭代,也能用来做严格的发布决策。
HUE用原子二元验证来评估视频生成质量。每个生成的视频会被拆成跨越四个维度(语义对齐、物理定律、几何推理和视觉完整性)的单事实是/否问题,覆盖机器人、自动驾驶汽车和物理学等七个物理AI领域。这些问题由一个VLM流程生成,经过人类专家完善,也在Hugging Face上开源了。
基准测试结果
Cosmos 3已经在好几个基准测试套件里评估过了,覆盖物理AI推理、生成质量和特定领域性能。
推理基准
Cosmos 3 Super和Cosmos 3 Nano分别在320亿参数和80亿参数层级上,在VANTAGE-Bench里领先:
- VANTAGE-Bench:第一个评估视觉语言模型在仓库、交通这些真实世界固定摄像头录像上表现的公共基准。