MiniMax M3 今天正式发布。
这模型在编码和智能体这类专业任务上,水平到前沿了。它用了我们团队搞的新注意力架构 MSA,支持高达 100 万 token 的超长上下文。大家一直等的原生多模态也上了,支持图像视频输入,还能操作电脑桌面。
这三种能力,现在已经是闭源前沿模型的标配了。M3 是第一个,也是目前唯一一个把这三样都合起来的开放权重模型。
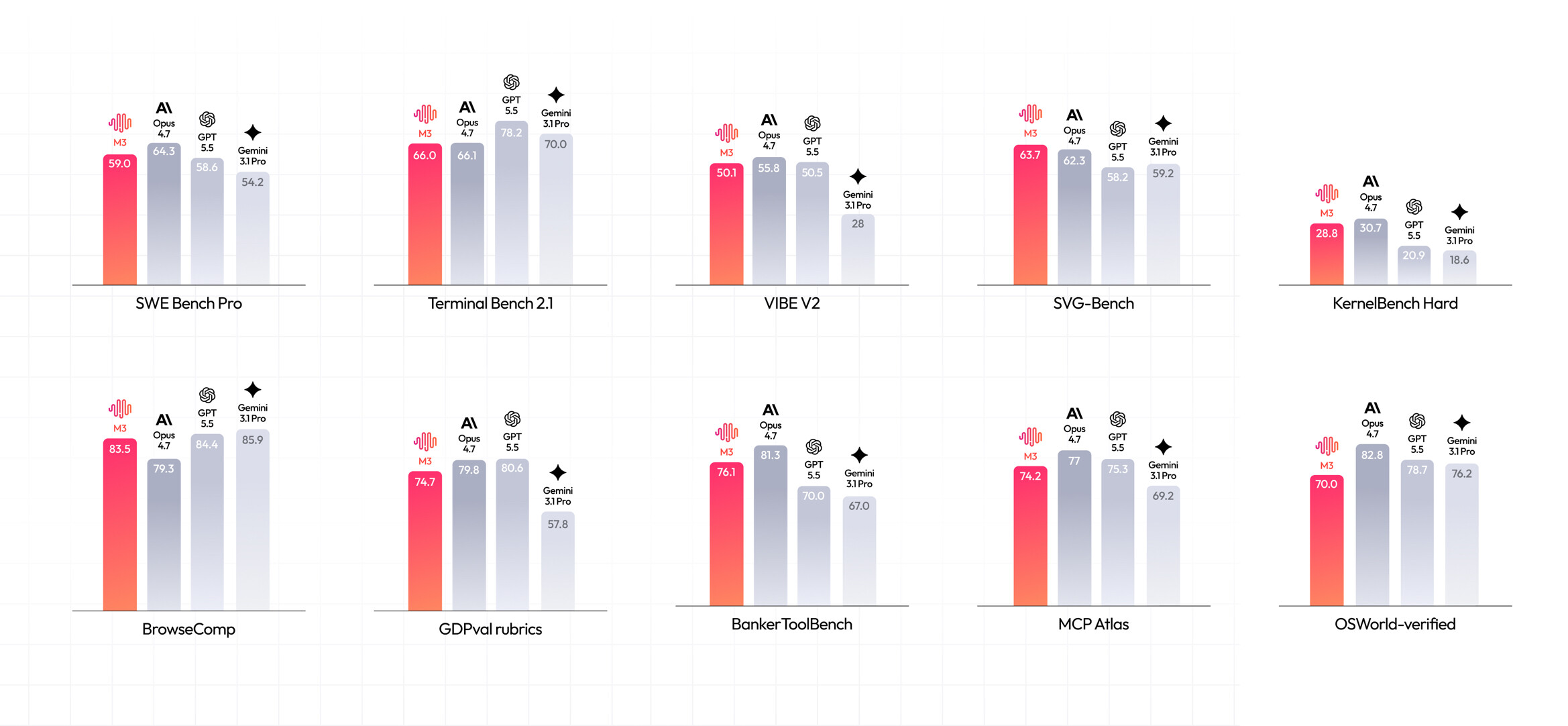
在测编码的 SWE-Bench Pro 上,M3 超过了 GPT-5.5 和 Gemini 3.1 Pro,接近 Opus 4.7。在测 SVG 生成的 SVG-Bench 上,M3 也超过了 Opus 4.7。
多模态基准 OmniDocBench 上,M3 分数比 Gemini 3.1 Pro 高。测自主智能体的 Claw-Eval 框架上,M3 拿了最高分。
现在就能通过 MiniMax Code、Token Plan 和我们的 API 来体验 M3。
MSA:靠架构创新扩展上下文
我们训 M3 的时候,解决更复杂的智能体任务是主要目标之一,其中一个大挑战就是扩展上下文。想真有突破,就得从最底层——注意力机制——动手,避开全注意力的“天生缺陷”:二次方计算复杂度增长。
MSA 是一种简洁、好扩展的新型稀疏注意力架构。它让 M3 有了 100 万的上下文窗口,让上下文真正变成一个能扩展的维度。
稀疏注意力一般会加个预过滤阶段来避免复杂度爆炸。和 DSA、MoBA 这些比,MSA 能更准地把 KV 切成块,实现更高的有效上下文覆盖率。
同时,我们在算子层面也做了直接优化,用了“KV 外循环聚集 Q”的法子,就是用 KV 块当外循环,去聚集命中它的查询。每个块只读一次,内存访问是连续的;在 M3 的头部配置下,算术强度比常见方法强得多——比开源 Flash-Sparse-Attention 和 flash-moba 快 4 倍以上。
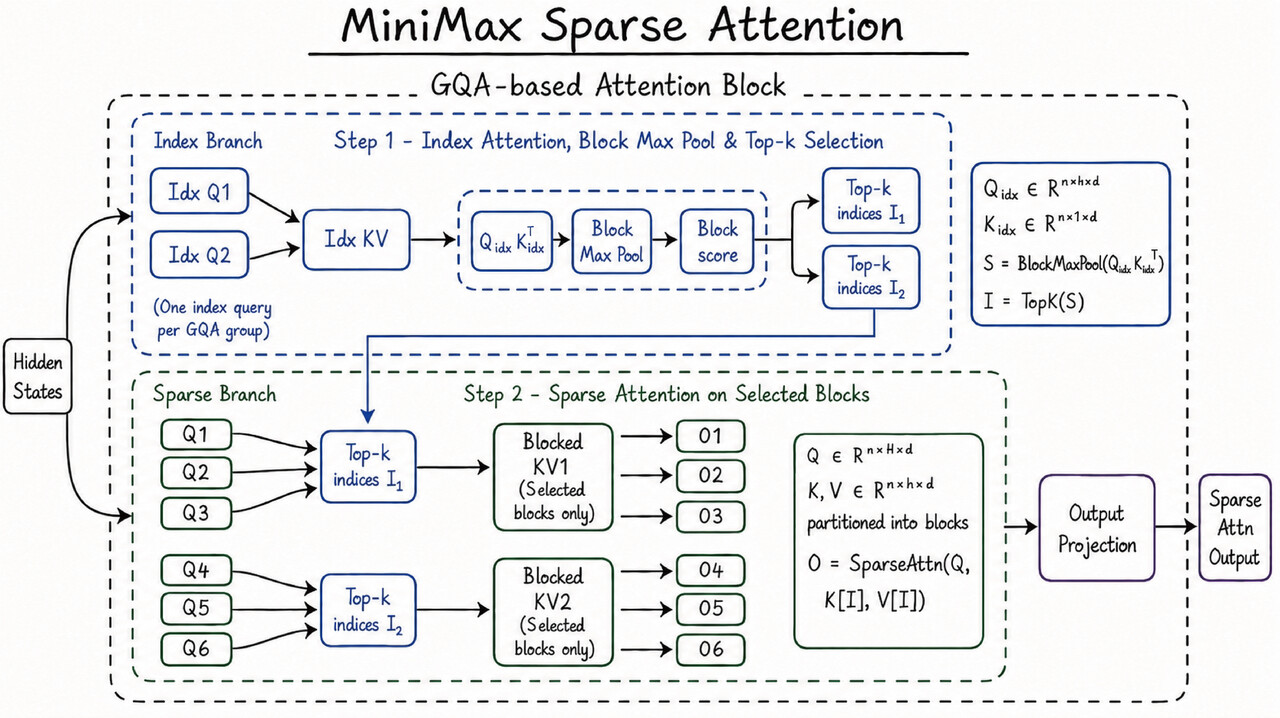
它简洁、可扩展、好实现、对硬件友好,所以理论上的好处能在实际里体现出来:在 100 万上下文长度时,M3 每个 token 的计算量只有上一代模型的 1/20。我们在预填充阶段实现了超过 9 倍的加速,解码阶段超过 15 倍加速。另外,在多次消融实验里,MSA 在大多数能力上都和全注意力差不多。
前沿编码和智能体能力
编码和智能体能力是 M3 重点改进的地方。在一些国际公认的软件工程和终端执行基准测试里,M3 达到了前沿水平:
- SWE-Bench Pro:59.0%
- Terminal-Bench 2.1:66.0%
- SWE-fficiency:34.8%
- KernelBench Hard:28.8%
- MCP Atlas:74.2%
现在,编码能力越来越看模型能不能用真实世界的用户逻辑来训练。现有的编码基准经常抓不住真实的用户体验。
现在大多数代码智能体的训练和评估都假设是单轮任务。但现实不是这样。用户通常在一个会话里持续协作:澄清需求、调方案、跨上下文分配任务,根据中间结果反复迭代。
为了缩小基准测试和真实体验的差距,我们搞了个交互式用户模拟框架。
通过模拟真实开发者在协作时的行为模式,这个框架在训练和评估时,把模型暴露在更接近生产环境的交互场景里。它能模拟需求细化、方案讨论、基于反馈修正、持续任务切换和复杂项目迭代这些行为。这样,智能体就不只是被动执行指令,而是能主动跟用户协作完成任务。
下一代智能体编码的衡量标准,不只是代码生成,还得看长期协作能力、规划能力,以及人机协作的效率。M3 扩展了对编码和智能体真正重要的数据,目标不只是在基准测试里领先,还要成为真实世界研发工作流里,开发者能靠得住的协作伙伴。
多模态:交错训练,持续扩展
M3 是从第 0 步就开始混合模态训练的模型。这种原生多模态方法,让不同模态的语义空间能更自然、更深地融合。
同时,在数据混合和构成方面,我们做了大量实验,发现交错数据对提升模型性能的作用,比大家通常想的更关键。
这种文本和图像(或其他模态)在序列里自然交错的数据类型,对扩展整体训练数据也很重要。为这种数据重建了整个数据流水线之后,我们现在能把训练数据扩展到 100 万亿 token 的量级。
现实世界任务
我们在内部用和测试 M3 的时候,有几个现实世界任务印象挺深。
独立论文复现
作为前沿模型的三个基本能力,我们想看看,当 100 万超长上下文、顶级编码和智能体能力,还有原生多模态,在一个长线程里结合起来解决复杂任务时,会咋样。
我们给了 M3 一篇 ICLR 2025 的杰出论文《Learning Dynamics of LLM Finetuning》,让它独立复现。这论文研究了大模型微调时的“学习动态”。最后,M3 自主运行了快 12 小时,整个过程里独立搞出了 18 次提交和 23 张实验图,成功完成了核心实验。
它不仅成功匹配了 SFT 阶段预测概率变化的趋势,还清楚地观察到了 DPO 实验里强调的挤压效应,并成功验证了原论文提出的 Extend 缓解方法。
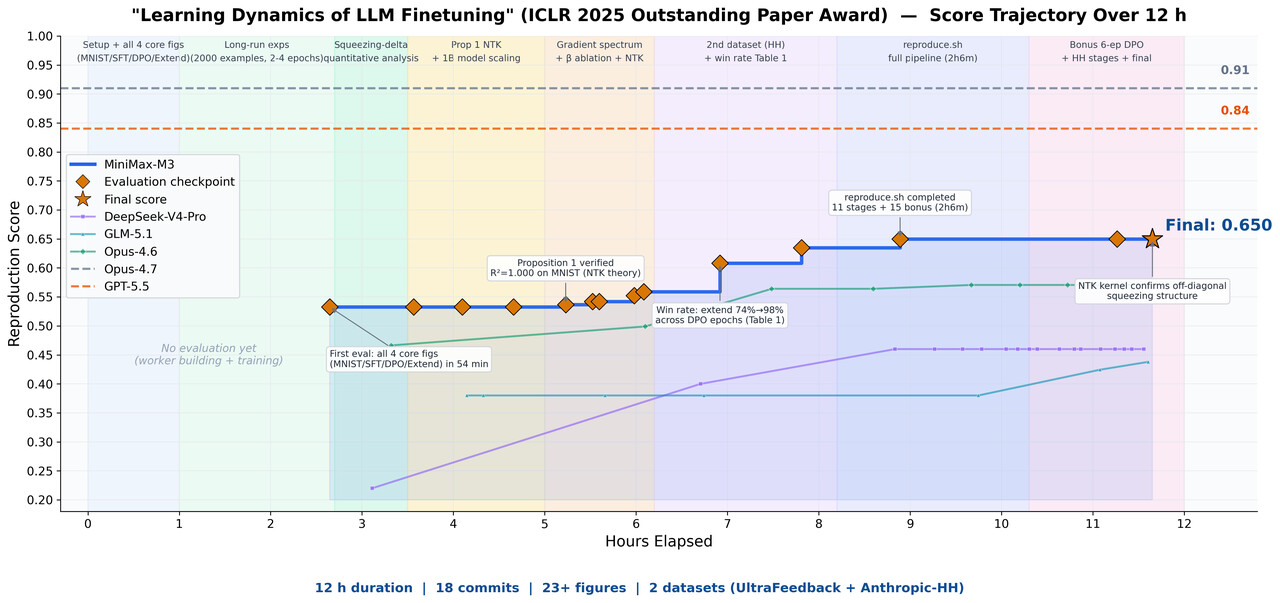
理解论文里的曲线、数据和公式需要多模态能力,长上下文保证了论文、代码和实验日志都能一次性塞进上下文窗口。只有编码和智能体能力够强,模型才能在一个长线程里完成复现,哪怕是并发执行。
M3 做到了。
CUDA 内核优化
FP8 矩阵乘法(GEMM)是大模型推理里计算最密的部分之一,也是最难优化的部分之一。工程师得同时处理多个紧耦合的问题,包括数据布局、计算流水线调度,还有对硬件特性的适配。在 NVIDIA Hopper 架构 GPU 上,手写一个生产级的 FP8 GEMM 内核,通常需要一个有经验的团队一到两周的专注工作。
我们用这个任务来评估 M3 的长期自主迭代能力。我们让 MiniMax M3 在 NVIDIA Hopper 架构 GPU 上优化这个内核。模型开始只有一个任务描述、一个基准评估脚本和一个不能直接跑的 Triton 骨架,没有可参考的高性能实现。这意味着模型没法靠模仿现有方案走捷径;它得从第一性原理出发,自己探索优化路径。
在接下来大约 24 小时的连续执行里,M3 完成了 147 次基准提交和 1959 次工具调用。它独立经历了从基线实现到生产级优化的整个过程,包括基线实现、自动调优配置生成、性能瓶颈诊断、CUDA Graph 集成、持久化内核重写和主机端调度优化。每一步都通过基准测试反馈自我验证,不用人管。
最终,经过六个里程碑式的优化轮次,M3 把 Hopper FP8 硬件峰值利用率从第一版的 7.6% 提到了 71.3%,和原始版本比实现了 9.4 倍的加速。
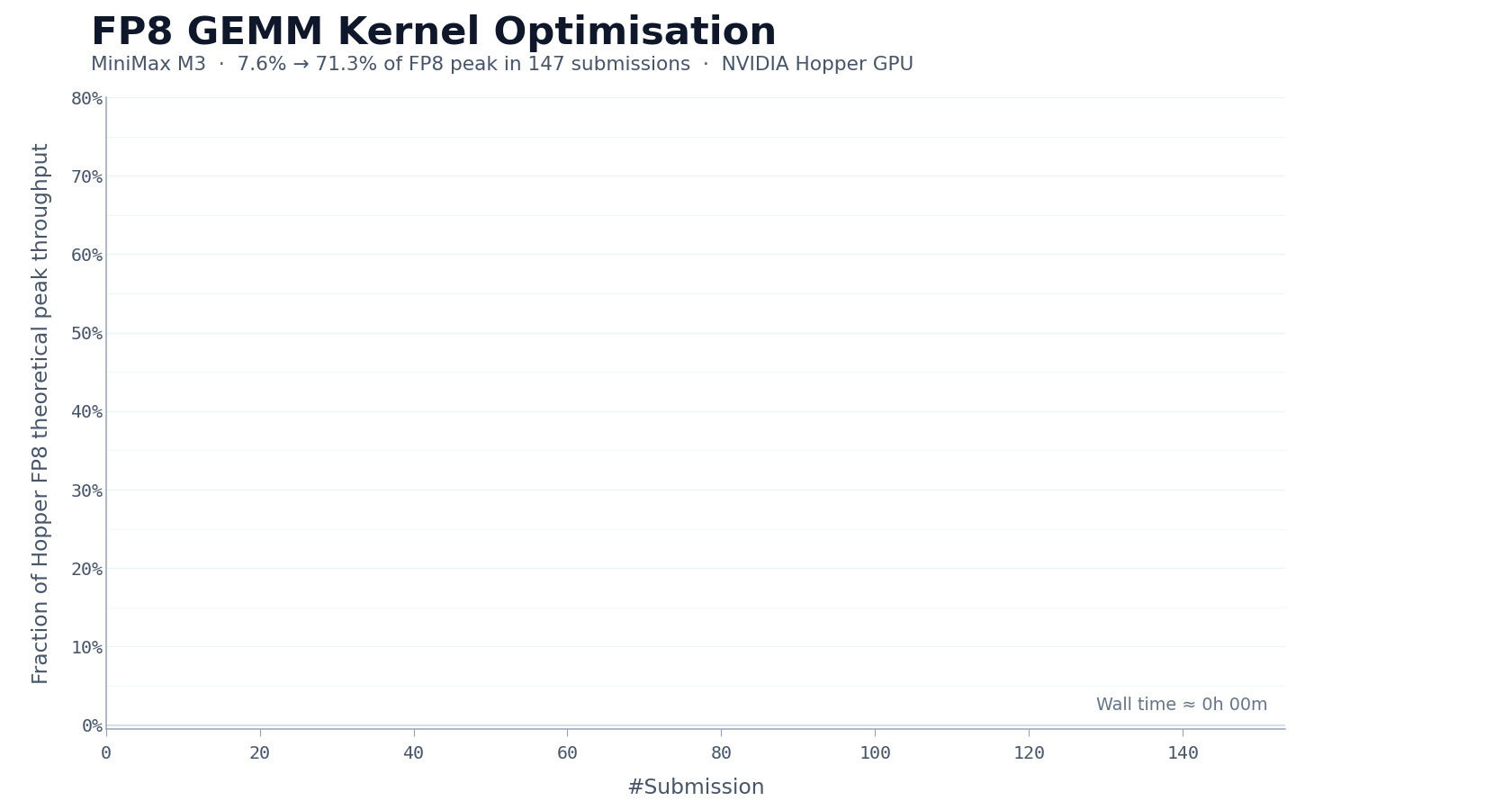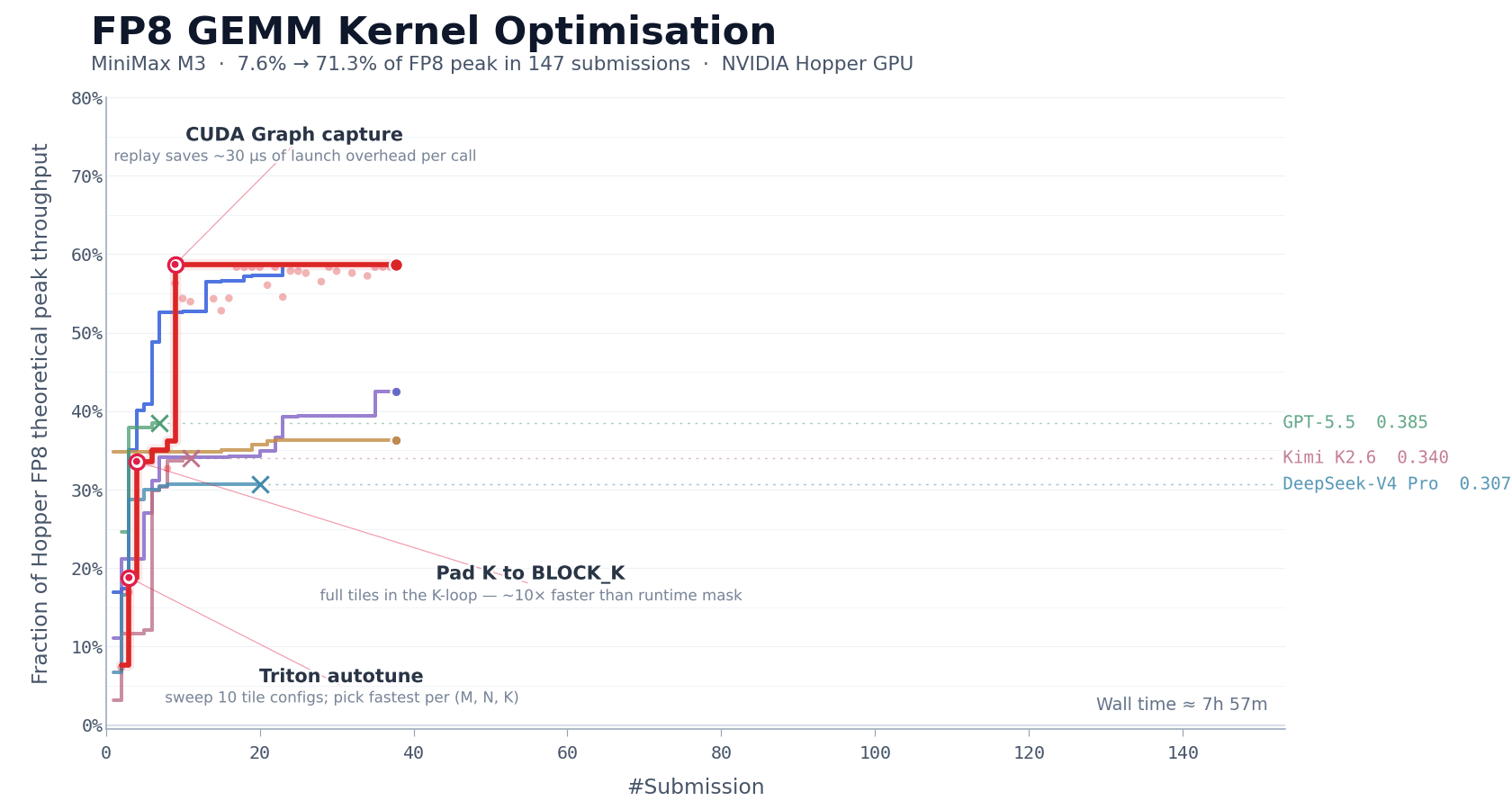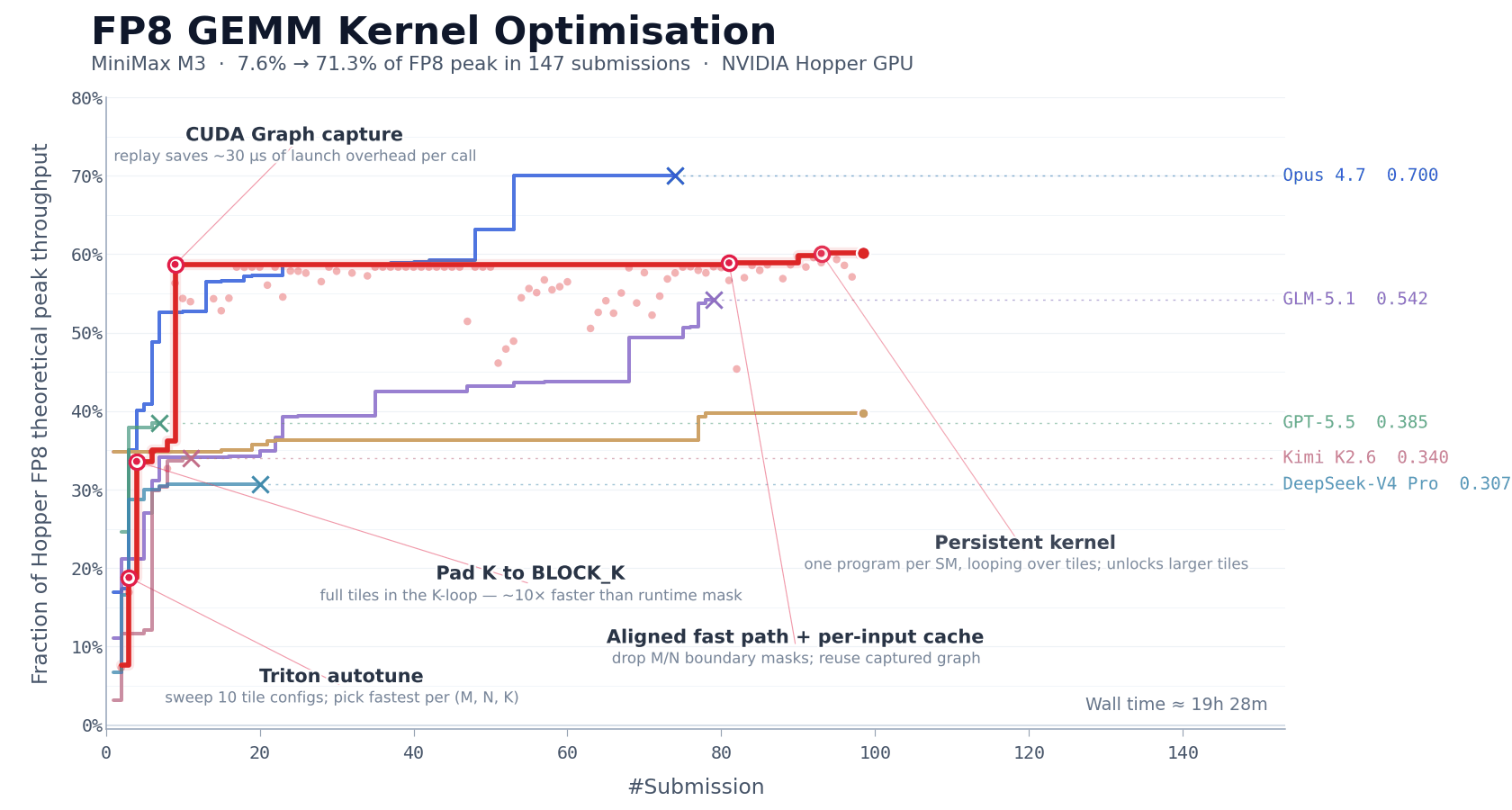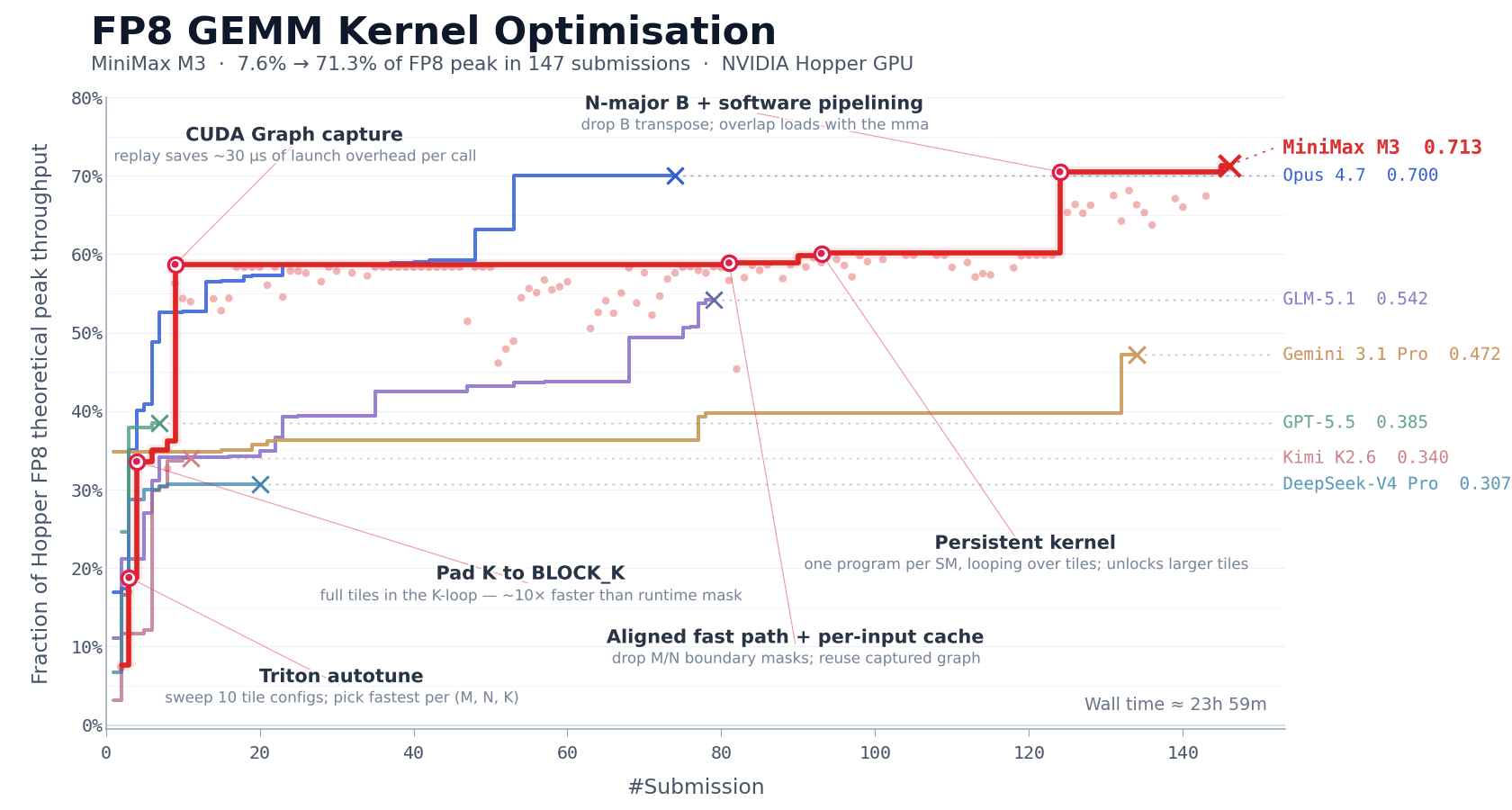
除了指标,模型的执行过程也值得注意。除了 Opus 4.7 和 M3,大多数其他模型在前 30 次提交内就没新进展,自己退出了。但 M3 的最佳方案出现在第 145 次提交。在这之前,模型经历了好几次性能平台期,没看到进一步改进,但它还是继续探索不同的方向。
这里需要的能力超出了传统代码生成。重复工具调用产生的上下文是高度结构化和密集的,而这正是 MSA 的长上下文注意力分配机制起作用的地方。
让 M3 训练模型
在 CUDA 算子优化任务里,M3 展示了它在单一工程任务上的长期迭代能力,那任务有明确的优化目标和清晰的反馈信号。但真实的研究工作往往没这么清晰的反馈结构;研究人员通常面对更开放的问题。
我们想了解 M3 在需要自主决策的场景里表现咋样,所以在 PostTrainBench 上测了它。任务是这样:给 M3 四个只做了预训练、还没有任何下游能力的 Base 模型,让它自己在 12 小时内完成数据合成、训练、评估和迭代的整个过程。最终目标是让这些模型在数学推理(AIME2025)、工具调用(BFCL)、科学知识推理(GPQA Main)、基础算术推理(GSM8K)和代码生成(HumanEval)上获得基本能力。
整个“数据合成 → 训练 → 评估 → 迭代”过程没人管。智能体得自己决定合成啥数据、选哪种训练策略,以及怎么根据评估结果调整下一轮计划。M3 最终得分 0.37,比 Opus 4.7(0.42)和 GPT-5.5(0.39)低一点,但明显领先其他模型。
MiniMax Code
随着 M3 发布,MiniMax Code 也更新了。作为一款专为 M3 设计、和 M3 一起训练的智能体产品,MiniMax Code 能充分利用 M3 在长上下文、编码/智能体任务和原生多模态方面的能力,让它成为和 MiniMax-M3 配对的首选智能体。
对于长期复杂的任务,MiniMax Code’