Stability AI,就是搞Stable Diffusion的那家公司,又整了个新的音频模型系列,叫Stability Audio 3.0。他们号称,最顶配的那个模型能生成超过6分钟的专业级音乐。
这次在Stable Audio 3.0名下放了四个新模型:小特效模型(4.59亿参数)、小模型(4.59亿参数)、中模型(14亿参数)和大模型(27亿参数)。两个小模型适合在设备上生成最长两分钟的音效和音乐。
中模型和大模型都能搞出6分20秒的完整曲子,而且能保持音乐结构和旋律调性。这比他们2024年发布的Stable Audio 2.0能生成的长度翻了一倍还多。
Stability AI这次把小特效、小、中这三个模型都开放了权重,谁都可以用和改。2024年他们放出的那个Stable Audio Open,最多只能生成47秒的音乐。跟之前的开源版本比,这次的新模型系列算是迈进了一大步。
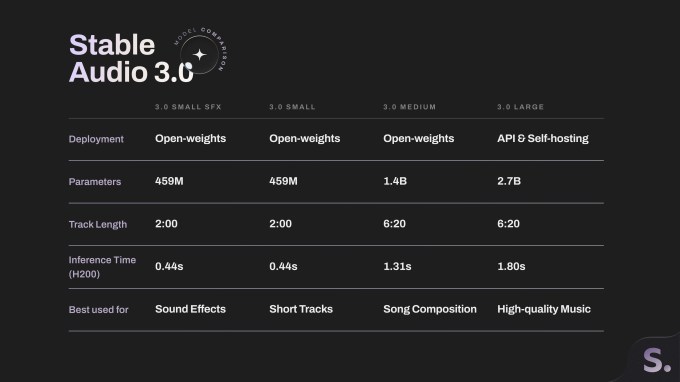
大模型只能通过API和付费的自托管服务来用。另外,年收入超过一百万美元的公司得去搞个企业许可证。
现在好多公司,比如Google和ElevenLabs,都在搞音乐生成的模型和工具。不过,从Suno和Udio正在打的官司就能看出来,数据授权和跟音乐厂牌的合作,可能成了这些服务能不能长期活下去的关键。
去年,Stability AI跟华纳音乐和环球音乐都签了协议,一块开发模型和音乐创作工具。公司说他们这套最新的音频模型,就是用完全获得授权的数据训练出来的。
这家AI初创公司还在为专业音乐人开发一套新产品,但具体有啥功能没细说。前Universal Audio和Fender的首席数字官Ethan Kaplan加入了他们,负责领导专业音乐这块的业务。
不少AI公司都在招音乐行业的高管来给自己背书。今年早些时候,Suno就聘了前Merlin的CEO Jeremy Sirota当首席商务官。ElevenLabs也从独立音乐发行商Kobalt挖来了Derek Cournoyer,负责他们音乐业务的战略。
(后面是作者信息和一些声明,跟新闻内容关系不大,我就不转了)