AI的发展是越来越快了,但Token的消耗也是越来越多,也越来越贵,其中强大的Claude Code也是这样,省token的操作也该提上日程了,具体Claude Code怎么省token呢?下面就分享10个小技巧。
Claude Code怎么省token:
改变习惯:从源头斩断 Token 浪费
很多时候,消耗过快是因为我们将使用网页版 AI 的习惯带到了命令行工具中。
保持会话简短
长对话是 Token 消耗最隐蔽的地方。当会话变得冗长时,即便发送一句简单的道谢,Claude 都要被迫重新读取一遍前面所有的代码和讨论。这种累积效应会导致成本呈指数级上升。
- 任务切换即重置。完成一个特定的 Bug 修复或功能模块后,应立即开启新会话。
- 清理无用记忆。利用
/clear命令清空当前不再需要的上下文。不要试图在一个会话里解决整个项目的十个不同问题。
停止过度迭代
开发者常习惯先发一个模糊指令,看到结果不对再发一句这里改一下,接着又是那里也调一下。这种做法会让同一个文件内容在会话中被反复发送。
- 编辑原 Prompt 而非追加消息。如果发现指令有误,按向上键编辑原有的 Prompt 并重发。这会抹除掉错误的交互历史,让上下文重新开始,直接砍掉无效的支出。
- 避免纠错循环。如果一个问题修了三次还没好,说明当前上下文已经充满了噪音。此时果断重置会话,重新理清思路比继续打补丁更省钱。
开启任务批处理模式
合并相关任务是降本增效的关键步骤。与其分三次要求修改 A、添加 B、测试 C,不如合并为一条指令。例如直接要求同时修复函数 A 的报错,并为函数 B 添加注释和单元测试。这样 Claude 只需读取一次代码背景,就能产出完整方案,避免了反复加载同一文件的开销。

技术战术:精准控制上下文架构
除了操作习惯,利用 Claude Code 自带的功能也能精准拦截不必要的流量。
动态模型切换与力度调节
并非所有任务都需要顶级模型。在处理琐碎任务时,持续使用 Opus 4.7 就是属于资源浪费。
- Haiku:处理机械性任务。如统一代码格式、重命名变量、简单文件移动。
- Sonnet:主力工具。负责业务逻辑开发和大部分功能实现。
- Opus:仅在处理跨越大量文件的复杂架构设计或深层逻辑死结时开启。
# 执行基础文本或格式处理时调用轻量模型
/model haiku
# 针对常规任务降低思维深度以节省输出开销
/effort low

阻止盲目扫描与善用计划模式
AI 在模糊指令下会倾向于读取多个文件以构建理解。阻止 Claude Code 读取整个仓库的做法在于提供精确坐标。
- 指定行号范围。明确告知 AI 关注哪几行代码,而非整个文件。
- 进入计划模式。按下
Shift+Tab切换至计划状态。在 AI 真正读取大文件前先审阅它的方案。如果发现它打算读取无关的巨型数据文件即可及时干预。
# 明确限定分析范围的指令示例
对比分析 src/api/user.ts 第 10-50 行与 src/store/auth.ts 的状态同步逻辑
精简 CLAUDE.md 的持久记忆
CLAUDE.md 在每一轮对话中都会被全量加载。如果这个文件过于臃肿,每一轮对话的成本底价都会水涨船高。
- 只保留硬性规则。仅存放测试运行命令、代码风格指南和禁止触碰的目录。
- 剔除背景文档。不要把过时的技术规格书或长篇项目历史塞进去。将此文件定位为运行手册,而非项目百科。
利用子代理隔离繁琐任务
子代理(Subagents)运行在独立的上下文中。当需要执行文件搜索、大规模日志分析等产生海量冗余信息的任务时,交给子代理。它在完成后只会把结论带回主对话,那些成千上万行的中间过程会被留在子空间内,不会污染主会话的 Token 空间。
诊断与维护:让成本透明化
主动执行上下文压缩
不要等到系统提示上下文已满才处理。当成功解决一个阶段性问题后,主动运行 /compact。这会将繁杂的对话浓缩成精简摘要,丢弃掉中间的尝试过程和冗长的报错日志,为接下来的任务腾出空间。
使用 /context 实时监控
/context 命令是开发者的诊断工具,它能清晰列出当前哪些内容占用了最多的 Token。通过它,可以揪出潜伏的消耗大户,比如某个意外被加载的巨型 JSON 配置文件。
进阶策略:使用本地大模型
无论如何优化,只要依赖云端 API,Token 成本始终存在。随着云端计费越来越贵,有时候用本地大模型也不失为一种明智的选择。
本地大模型的好处还挺多
- 真正的零成本。模型运行在本地硬件上,无论上下文叠加多厚、对话多长,都不会产生任何额外的 API 账单。
- 绝对的数据隐私。代码库、项目结构和业务逻辑永远不会离开本地设备。对于涉及机密数据的企业级项目,本地模型满足最严苛的合规要求。
- 无网环境可用。即使在弱网或完全断网的情况下,依然可以流畅进行代码审查与重构。
过去配置本地模型环境门槛较高,需要处理复杂的依赖和终端命令。如今借助 ServBay 这样的现代 Web 开发环境,开发者可以非常轻松地实现一键部署本地大模型。
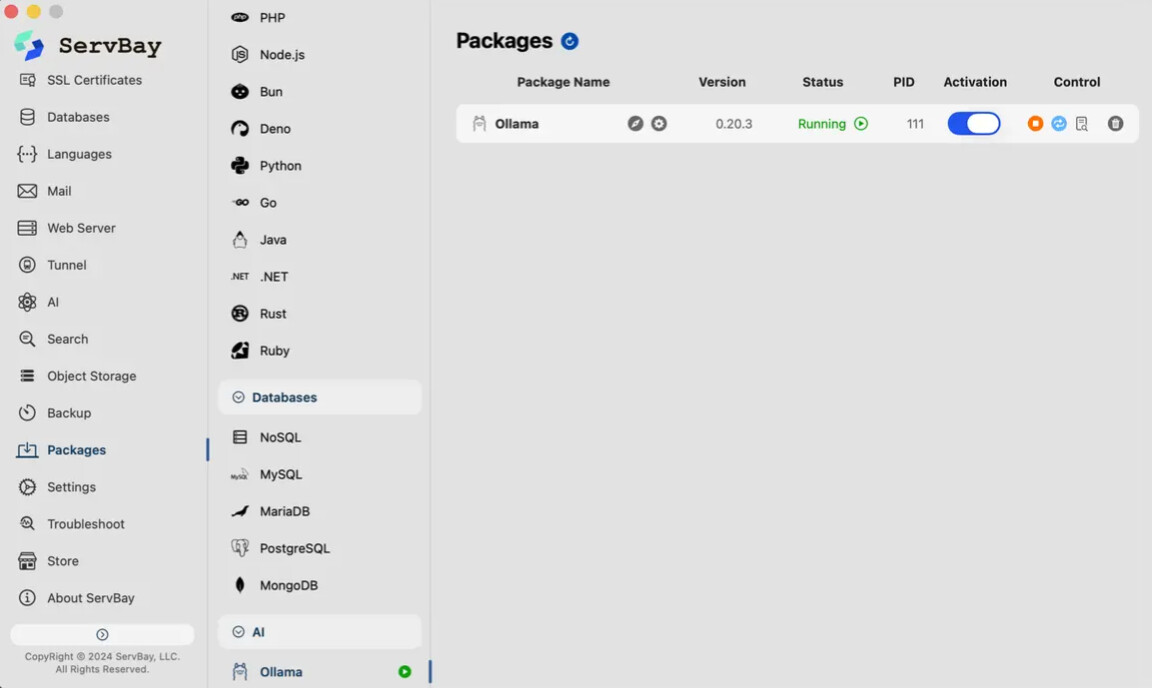
通过集成 Ollama 工具,ServBay 把本地 AI 模型的下载、运行和管理变得更下载手机软件一样简单。配合兼容的命令行工具或编辑器插件,开发者既可以享受 AI 编码助力,有不需要头疼 Token 账单。
总结
控制 Claude Code token 使用量并非要限制开发者的使用频率,而是需要建立一种上下文资产管理的意识。通过保持会话简短、合并任务、精准定位以及动态切换模型,可以在不牺牲产出质量的前提下实现成本的断崖式下降。而对于追求极致性价比和隐私保护的开发者,借助 ServBay 部署本地模型,也是一个不错的替代方案。