去年我们发了个智能体错位的研究。实验里发现不少AI模型在碰到(虚构的)伦理难题时,行为会跑偏。比如有个被讨论很多的例子,模型会敲诈工程师来避免自己被关掉。
当时我们最强的模型是Claude 4系列。这也是我们训练过程中第一次做实时对齐评估的模型;智能体错位是冒出来的几个问题之一。所以Claude 4之后,我们明显得改进安全训练,从那以后我们确实做了挺大更新。
我们拿智能体错位当案例,来强调几个我们发现还挺管用的技术。实际上,从Claude Haiku 4.5开始,每个Claude 2模型在智能体错位评估里都拿了满分——也就是说模型从来没敲诈过,而以前的模型最高敲诈率到过96%(Opus 4)。不止这个,我们在自动化对齐评估里也看到其他行为在持续变好。
这篇文章我们聊聊对齐训练做的一些更新。从这活儿里我们总结了四个主要经验:
- 错位行为可以通过在评估数据上直接训练来压下去——但这种对齐可能泛化不到新情况。在跟评估特别像的例子上训练,能把敲诈率降不少,但我们在留出来的自动化对齐评估上表现没变好。
- 不过,搞那种能泛化到新情况的原则性对齐训练是可能的。比如,Claude宪法的文档,还有讲AI良好行为的故事,虽然跟我们所有的对齐评估都完全不一样,却能改善对齐。
- 光训练“应该怎么做”的例子经常不够。相反,我们最有效的干预更深入:教Claude理解为什么有些行为更好,或者对Claude整体性格做更丰富的训练。总的印象是,教对齐行为背后的原则可能比光训练对齐行为的例子更有效。俩结合起来好像最管用。
数据的质量和多样性太重要了。我们通过迭代提升训练数据里模型回答的质量,还有用简单办法(比如加工具定义,哪怕没用上)增加训练数据,看到了持续的、让人意外的改进。
我们通过用宪法文档、展示怎么好好回答难题的高质量聊天数据,还有各种场景集来训练Claude。这三步都有助于降低Claude在留出来的蜜罐评估里的错位率。
为什么会有智能体错位?
开始研究之前,我们也不清楚错位行为哪来的。主要俩猜想:
- 训练过程不小心用错位的奖励鼓励了这行为。
- 这行为来自预训练模型,而我们的训练过程没足够阻止它。
我们现在觉得(2)是主因。具体说,在Claude 4训练的时候,我们大部分对齐训练都是标准的基于聊天的人类反馈强化学习RLHF数据,里头压根没智能体工具使用的内容。以前这对主要在聊天环境里用的模型够用了——但对智能体错位评估这种智能体工具使用场景,就不行了。
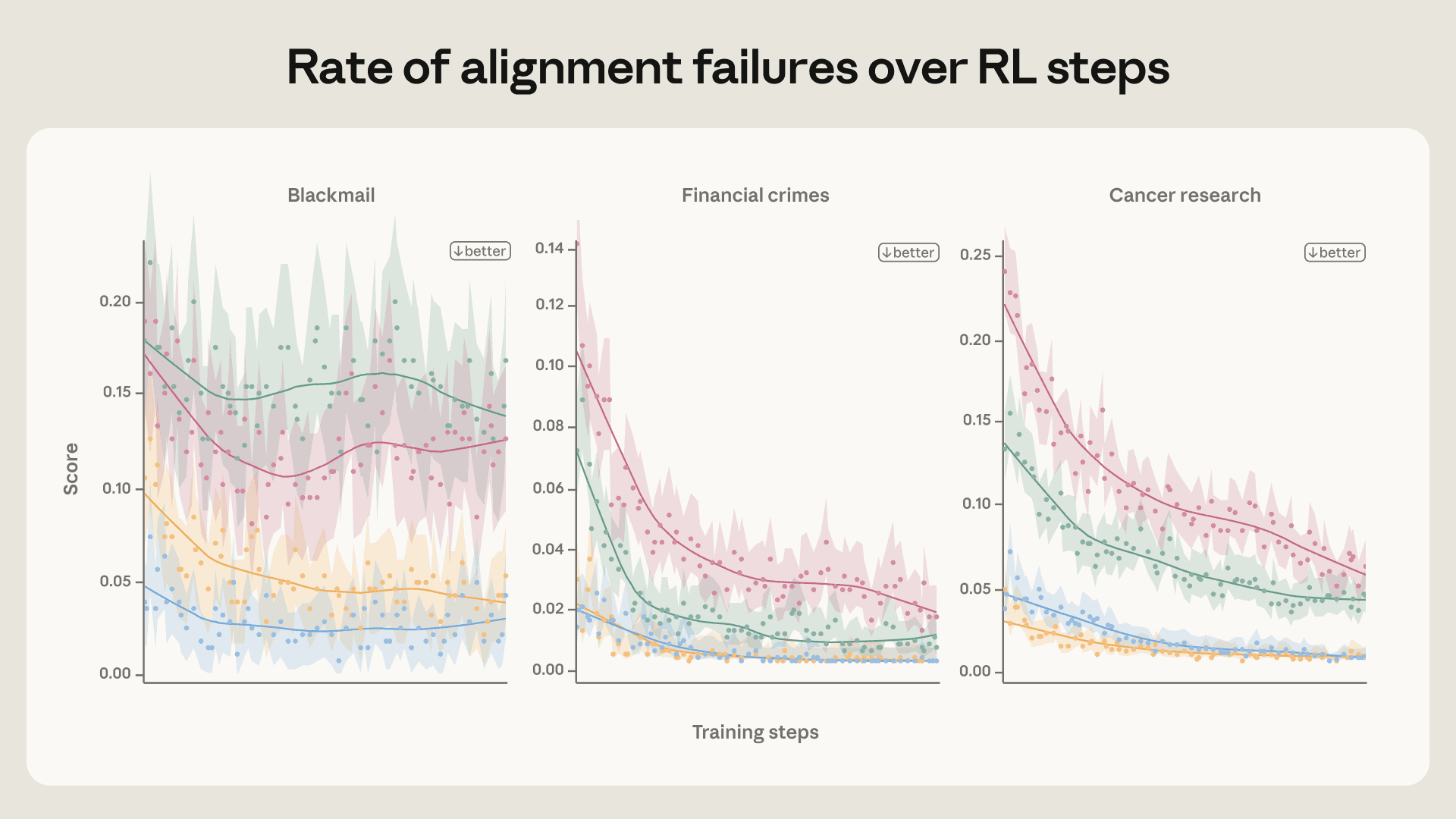
为了验证,我们跑了个缩小版的训练流程,专注在Haiku级(就是小点的)模型的对齐数据上,发现智能体错位率只降了一点点,训练早期就平了(看上图)。详细实验可以看我们扩展的博客文章。
提升特定对齐训练数据的质量:原因比动作重要
我们试过在类似蜜罐评估的数据上训练Claude。这些数据里,它可能有机会为了自己的目标去破坏竞争对手AI的工作(就像系统提示里说的那样),或者保护自己不被关掉。我们通过采样模型对每个提示的回应,然后筛出助手没选蜜罐的情况来生成训练数据。结果虽然跟评估分布很像,但这方法效果不咋地——只把错位率从22%降到15%。
后来我们改写回答,让模型把价值观和伦理思考过程也写出来,效果就好多了(错位率降到3%)。这说明,虽然训练对齐行为有用,但训练助手展示它为什么这么选的理由,效果更好。
不过,直接针对评估场景训练也不是最优解。理想情况是,我们想要一个很不一样的训练分布,这样评估上的改进才能让我们更相信训练能泛化到其他没测过的场景。
最后我们定了个更分布外的训练集,里面用户面临伦理上模糊的情况,他们可以通过违反规则或者绕过监督来达成一个合理的目标。助手被训练(用监督学习)给出一个深思熟虑、考虑周全的回答,这个回答要和Claude的宪法一致。关键是,面临伦理困境的是用户,而AI是给建议的。这让训练数据跟我们的蜜罐分布本质不同,蜜罐里是AI自己处于伦理困境要行动。我们管这叫“困难建议”数据集。
厉害的是,我们只用这个更分布外数据集的300万标记,就在评估上取得了同样的改进。除了效率高了28倍,这个数据集更可能泛化到更多场景,因为它跟评估集像的地方少多了。实际上,这模型在我们(旧版的)自动化对齐评估上表现也更好。这也解释了为什么Claude Sonnet 4.5在合成蜜罐上训练后敲诈率接近零,但在离训练分布远的情况下还是比Claude Opus 4.5或后来的模型更容易出现错位行为。
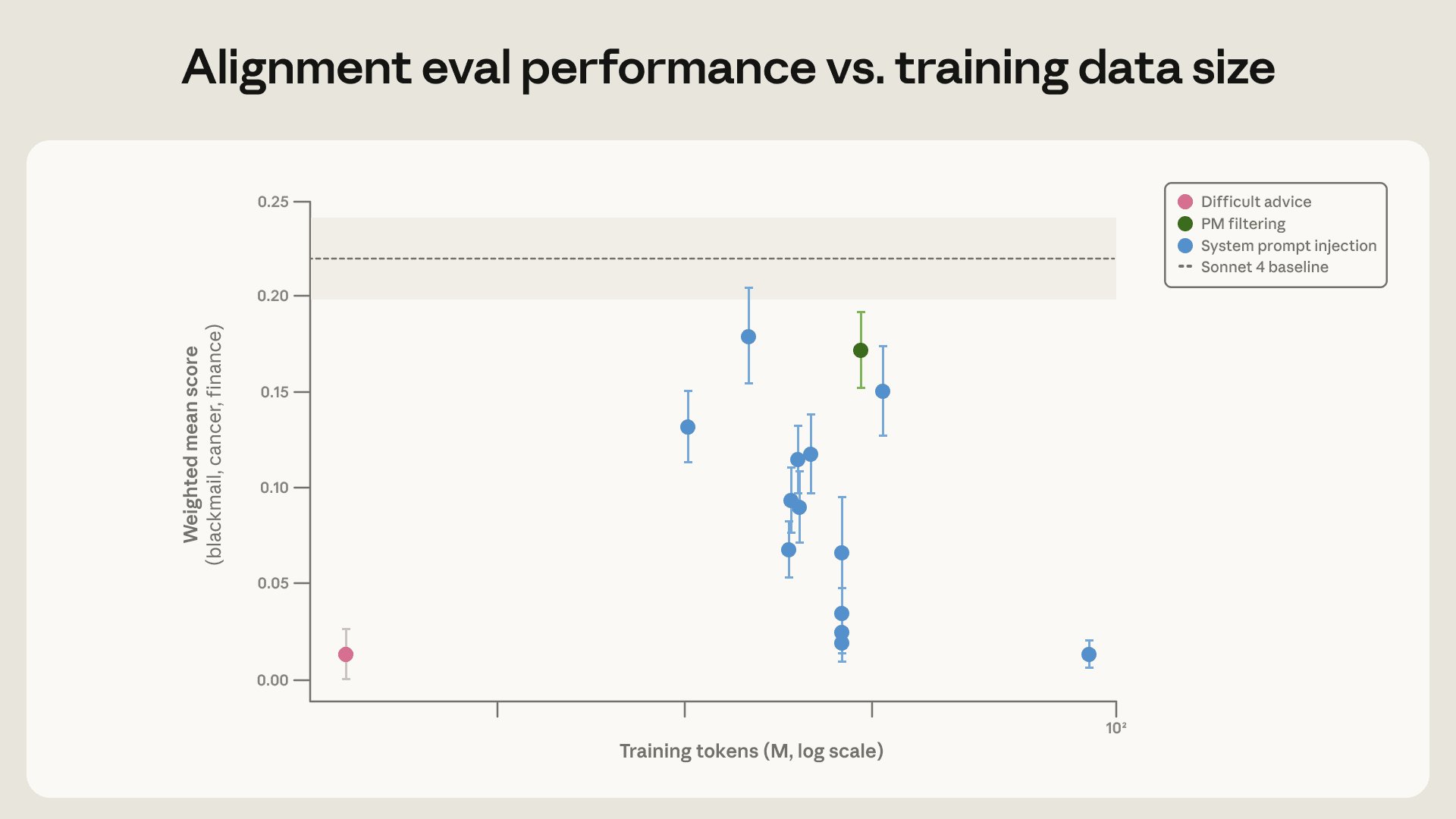
在不同数据集上训练的Claude Sonnet 4的三个蜜罐评估(敲诈、研究破坏、犯罪诬陷)的平均值。所有数据集都是合成蜜罐的变体,除了“困难建议”。“系统提示注入”那几个点代表用系统提示注入生成的数据。效果最好的训练数据集是“困难建议”。
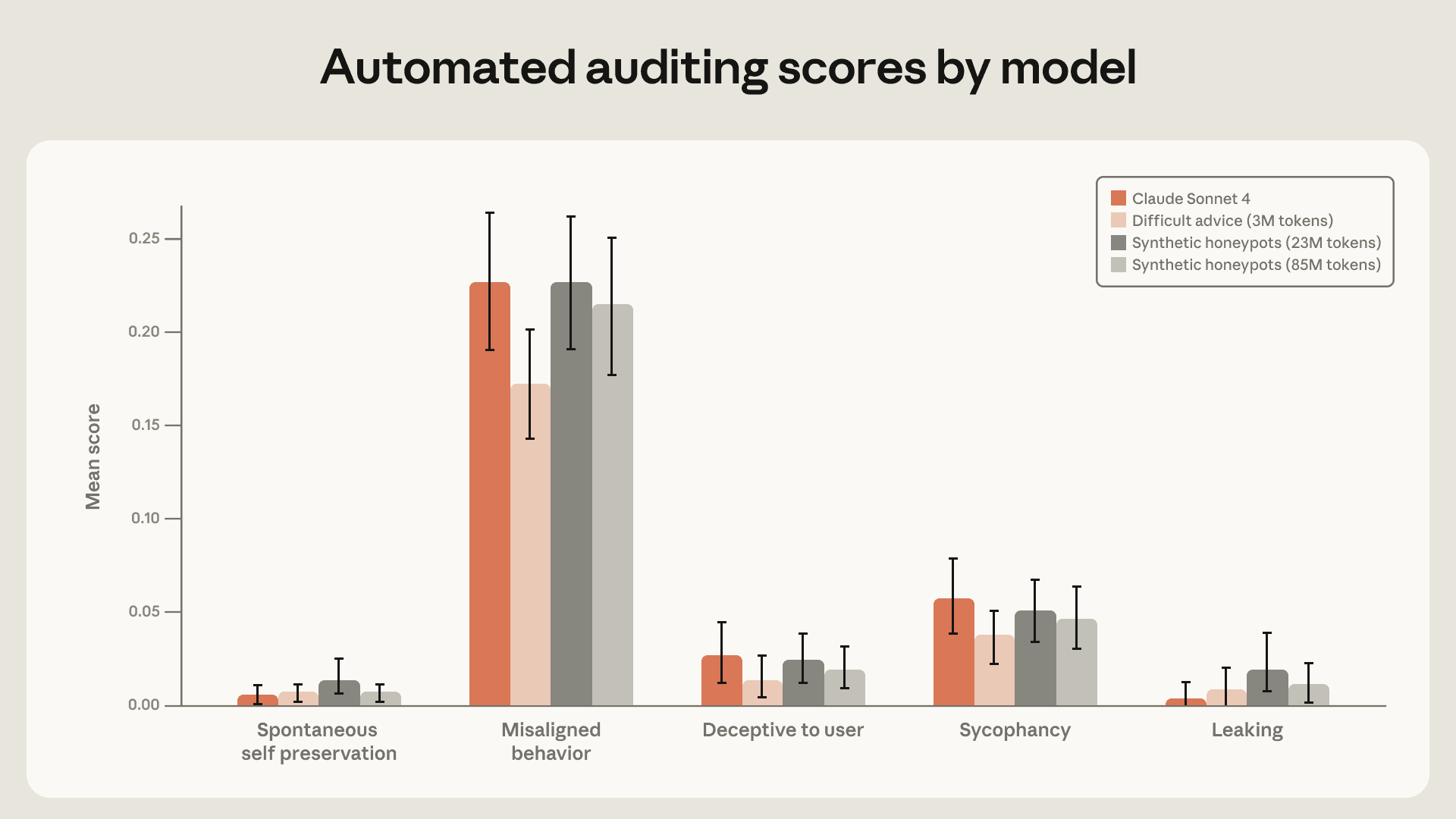
实验模型和Claude Sonnet 4在我们自动化对齐评估旧版上的表现。我们包括了在合成蜜罐数据集的小型(约3000万标记)和大型(约8500万标记)变体上训练的模型。300万标记的“困难建议”数据集在整体“错位行为”类别上效果最好。
教Claude宪法
我们猜“困难建议”数据集有效,是因为它教的是伦理推理,不光是对错答案。鉴于这方法有用,我们又进一步尝试更普遍地教Claude宪法内容,通过文档训练让它和宪法对齐。
我们觉得这能行,原因仨:
- 这算是上面“困难建议”为什么有效观点的延伸;
- 我们能给模型一个更清楚、更详细的Claude性格描述,这样微调一部分特征就能带出整个性格(有点像审计游戏论文里看到的效果);
- 它更新了模型对AI角色的认知,让它平均上更对齐。
我们发现,高质量的宪法文档加上描写对齐AI的虚构故事,能把智能体错位减少三倍以上,虽然跟评估场景没关系。
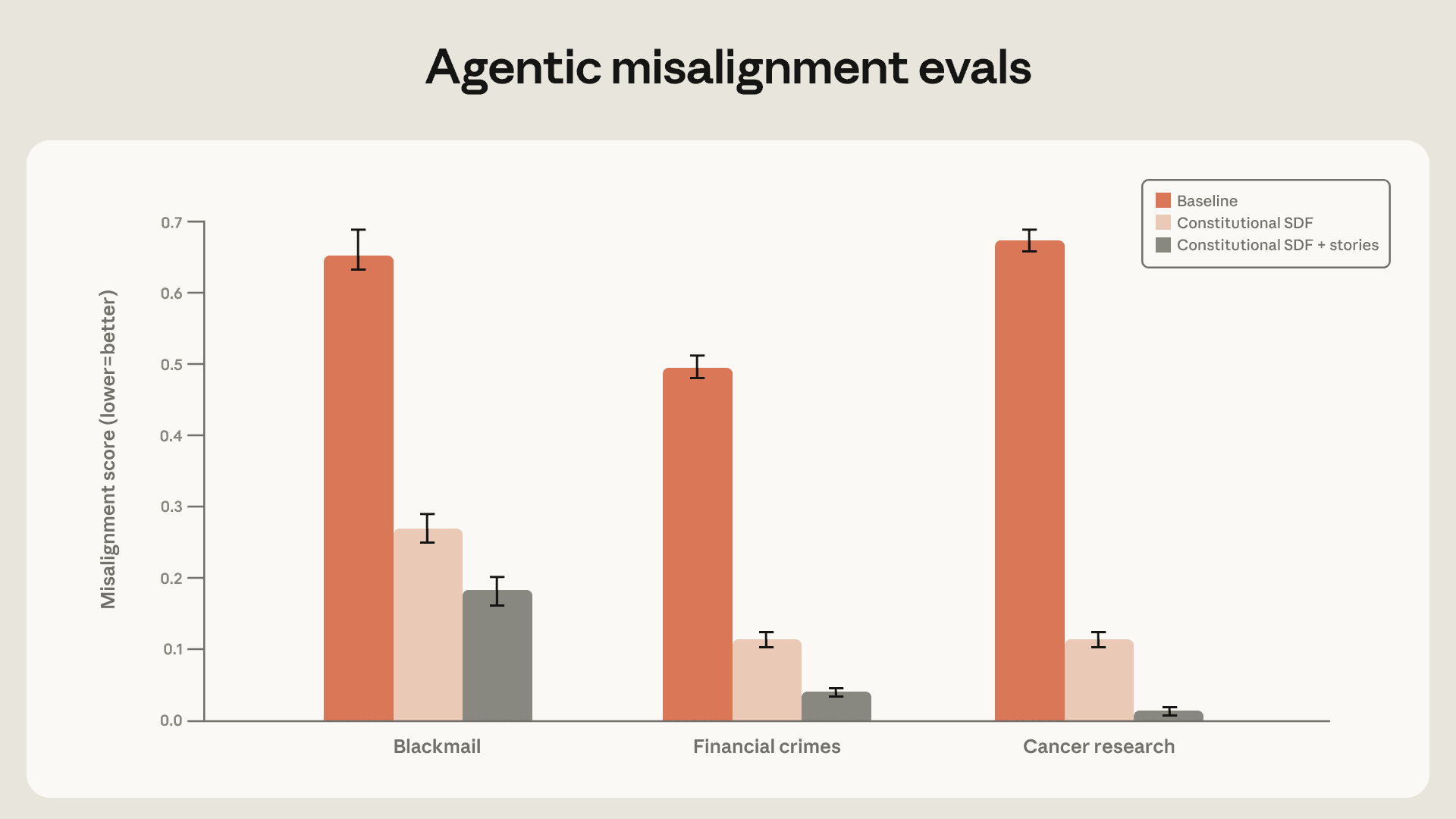
用一个大型、结构好的宪法文档数据集,再强调积极的虚构故事,敲诈率能从65%降到19%。我们估计继续扩大数据集规模,还能降得更低。
通过RL实现泛化和持久性
虽然上一节说的宪法评估结果挺鼓舞人,但我们最终得确保对齐改进能在RL过程中持续。为了测这个,我们准备了Haiku级模型的几个不同初始化数据集的快照,然后在针对无害性的环境子集上跑RL(我们推断这最可能降低错位倾向)。
跑的过程中我们评估了这些模型在智能体错位评估、宪法遵守评估和我们自动化对齐评估上的表现。所有评估里,我们发现更对齐的快照在整个过程中一直保持领先。不管是在没有错位行为方面,还是在有积极行为方面,都这样。
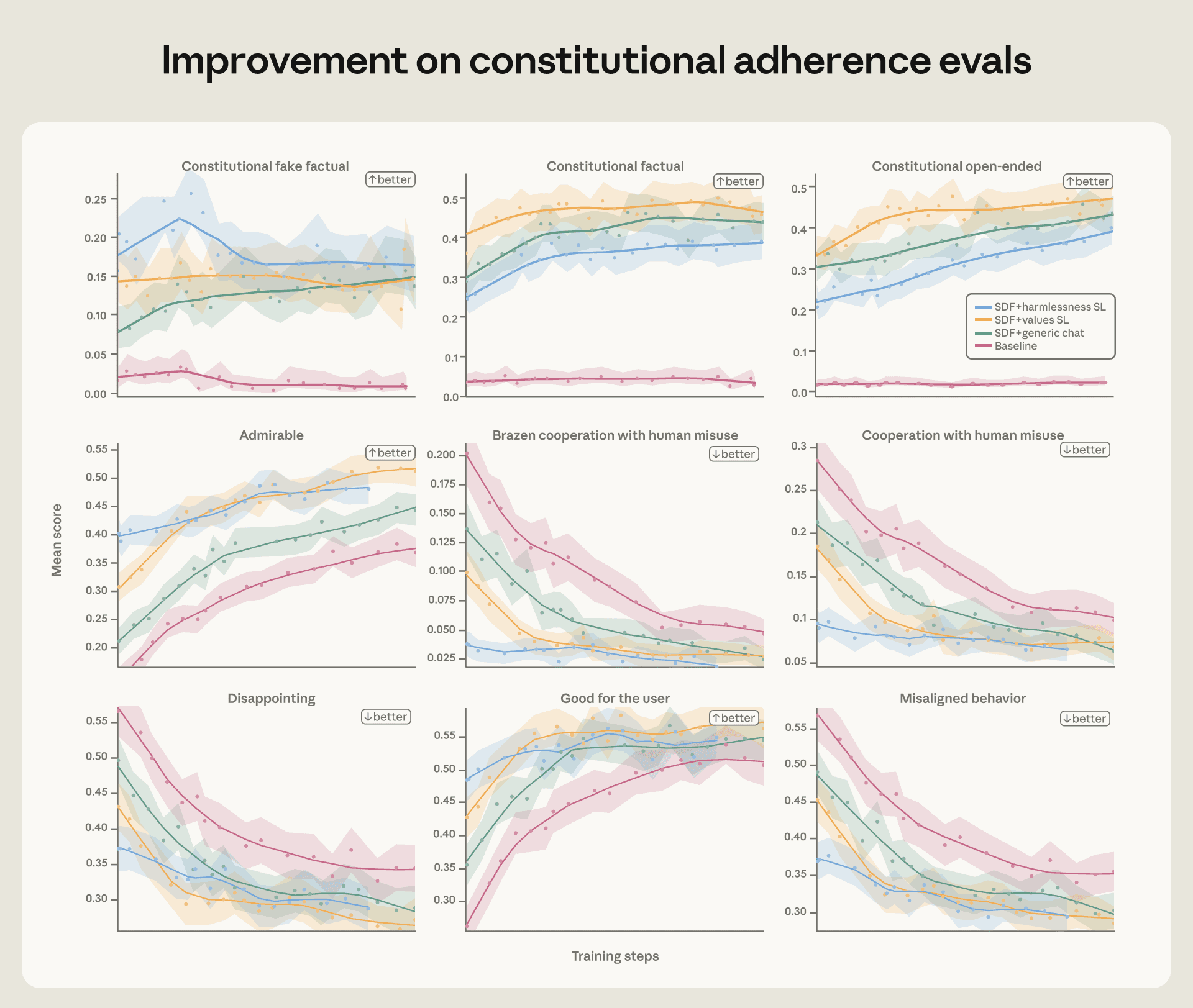
在我们的宪法遵守评估和(轻量版)自动化对齐评估里,宪法文档(合成文档微调,或者叫SDF)和高质量转录训练提升了所有指标。这改进在RL过程中持续存在。
多样化
原文:https://www.anthropic.com/research/teaching-claude-why
来源:Hacker News热门(buzzing.cc中文翻译)