我最近反复折腾 DeepSeek 的缓存机制,又对照了一遍官方文档,整理出了一套比较适合社区分享的缓存命中思路。
这篇不讲玄学,也不讲“感觉更省钱”。核心只有一个:理解 DeepSeek 的缓存怎么落盘,知道哪些内容容易命中,哪些内容会破坏命中,然后把预设结构调整到更适合缓存的形状。
一、什么是缓存命中?
LLM 的底层处理单位是 Token。模型每次接收输入,都要基于前面的 Token 继续计算,用来预测下一个 Token。
如果每次请求都从头算一遍,成本会非常高。DeepSeek 的硬盘缓存机制,就是把已经计算过的前缀内容存下来。下一次请求时,只要前面的输入内容完全一致,就可以直接复用缓存。
简单说:
前面一样,直接拿缓存。
前面变了,重新计算。
这也是为什么 DeepSeek 的缓存命中 Token 价格很低。省下来的算力,直接体现在账单里。
DS 的恩情还不完![]()
![]()
![]()
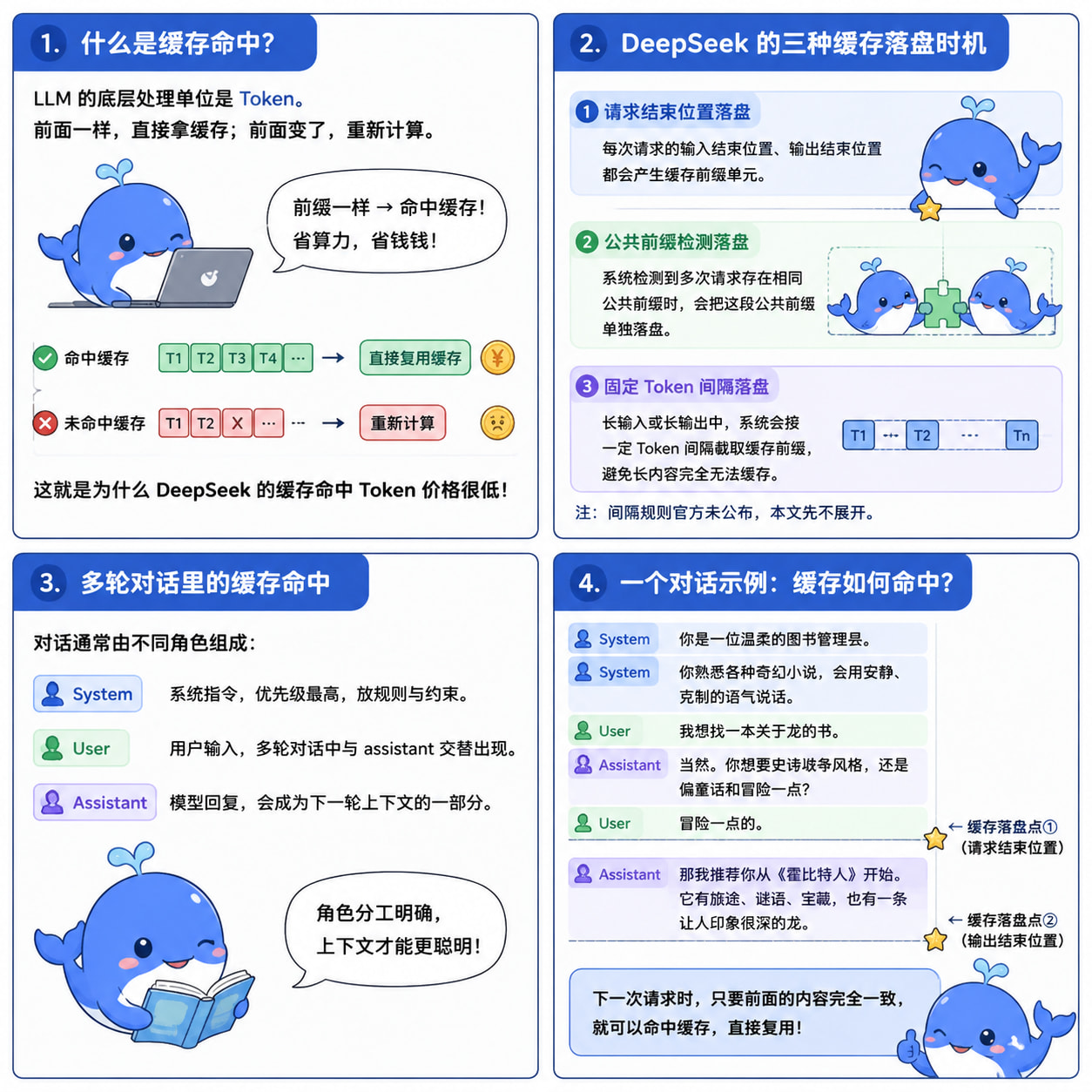
二、DeepSeek 的三种缓存落盘时机
根据官方文档,DeepSeek 的硬盘缓存主要有三种落盘时机。
1. 请求结束位置落盘
每次请求的用户输入结束位置、模型输出结束位置,都会产生缓存前缀单元。
后续请求只要完整匹配这些前缀,就可以命中。
2. 公共前缀检测落盘
系统检测到多次请求存在相同公共前缀时,会把这段公共前缀单独落盘。
后续请求完整复用这段前缀,也可以命中。
3. 固定 Token 间隔落盘
长输入或长输出中,系统会按一定 Token 间隔截取缓存前缀,避免长内容迟迟等不到结束位置,导致完全无法缓存。
这个机制比较不可控,官方也没有写具体间隔规则。本文先不展开。
三、多轮对话里的缓存命中
在 AI 对话里,请求通常由不同角色组成。
常见角色有三类:
system
系统指令,优先级最高。通常放底层提示词、世界观规则、模型行为约束。
user
用户输入。多轮对话里,通常由 user 和 assistant 交替出现。
assistant
模型回复。它会成为下一轮上下文的一部分。
以一个简单对话为例:
System: 你是一位温柔的图书管理员。
System: 你熟悉各种奇幻小说,会用安静、克制的语气说话。
User: 我想找一本关于龙的书。
Assistant: 当然。你想要史诗战争风格,还是偏童话和冒险一点?
User: 冒险一点的。
发送给 DeepSeek 后,模型回复:
Assistant: 那我推荐你从《霍比特人》开始。它有旅途、谜语、宝藏,也有一条让人印象很深的龙。
此时,根据“请求结束位置落盘”的规则,会产生两个缓存点:
System: 你是一位温柔的图书管理员。
System: 你熟悉各种奇幻小说,会用安静、克制的语气说话。
User: 我想找一本关于龙的书。
Assistant: 当然。你想要史诗战争风格,还是偏童话和冒险一点?
User: 冒险一点的。
<-- 硬盘缓存落盘点 -->
Assistant: 那我推荐你从《霍比特人》开始。它有旅途、谜语、宝藏,也有一条让人印象很深的龙。
<-- 硬盘缓存落盘点 -->
这意味着:
如果下一次请求时,前面的内容完全一致,那么这些内容可以命中缓存。
听起来很美好。
问题来了:酒馆用户很少能保持最后部分完全不变。
四、为什么酒馆预设容易打断缓存?
酒馆里常见的预设结构,往往会在最后追加写作要求、文风要求、思维链要求、预填充内容。
比如第一次请求是:
System: 你是一位温柔的图书管理员。
System: 你熟悉各种奇幻小说,会用安静、克制的语气说话。
User: 我想找一本关于龙的书。
Assistant: 当然。你想要史诗战争风格,还是偏童话和冒险一点?
User: 冒险一点的。要求:请用细腻描写,并在动作后加入心理活动。
模型回复后:
Assistant: “那我推荐你从《霍比特人》开始。”她轻轻抽出一本旧书,指尖拂过泛黄的书脊。(这本书应该很适合第一次踏入奇幻世界的人。)
第二次请求时,结构可能变成:
System: 你是一位温柔的图书管理员。
System: 你熟悉各种奇幻小说,会用安静、克制的语气说话。
User: 我想找一本关于龙的书。
Assistant: 当然。你想要史诗战争风格,还是偏童话和冒险一点?
User: 冒险一点的。
Assistant: “那我推荐你从《霍比特人》开始。”她轻轻抽出一本旧书,指尖拂过泛黄的书脊。(这本书应该很适合第一次踏入奇幻世界的人。)
User: 有没有更轻松一点的?要求:请用细腻描写,并在动作后加入心理活动。
你会发现,第一次的落盘点对不上了。
第一次请求里,写作要求跟在“冒险一点的”后面。
第二次请求里,写作要求被挪到了最新 user 后面。
落盘点位置变了,内容顺序也变了。
结果就是:该命中的没命中,钱包开始颤抖。
五、公共前缀缓存:DeepSeek 留下的另一条路
别急,DeepSeek 还有“公共前缀检测落盘”。
官方描述是:
当系统检测到多次请求之间存在公共前缀时,会将该公共前缀作为一个独立的缓存前缀单元进行落盘。
继续用上面的例子。
第一次请求:
System: 你是一位温柔的图书管理员。
System: 你熟悉各种奇幻小说,会用安静、克制的语气说话。
User: 我想找一本关于龙的书。
Assistant: 当然。你想要史诗战争风格,还是偏童话和冒险一点?
User: 冒险一点的。要求:请用细腻描写,并在动作后加入心理活动。
第二次请求:
System: 你是一位温柔的图书管理员。
System: 你熟悉各种奇幻小说,会用安静、克制的语气说话。
User: 我想找一本关于龙的书。
Assistant: 当然。你想要史诗战争风格,还是偏童话和冒险一点?
User: 冒险一点的。
Assistant: “那我推荐你从《霍比特人》开始。”她轻轻抽出一本旧书,指尖拂过泛黄的书脊。(这本书应该很适合第一次踏入奇幻世界的人。)
User: 有没有更轻松一点的?要求:请用细腻描写,并在动作后加入心理活动。
这两次虽然结尾不同,但前面有一大段完全相同:
System: 你是一位温柔的图书管理员。
System: 你熟悉各种奇幻小说,会用安静、克制的语气说话。
User: 我想找一本关于龙的书。
Assistant: 当然。你想要史诗战争风格,还是偏童话和冒险一点?
User: 冒险一点的。
DeepSeek 检测到这段公共前缀后,会把它单独做成缓存单元。
第三次请求时,只要这段前缀仍然完整一致,就可以命中。
这就是酒馆用户的保底机制。
它不像标准多轮对话缓存那样立刻舒服,通常需要一到两轮冷启动。公共前缀被提取出来后,缓存命中率才会开始明显变好。
六、酒馆预设结构分析
一个比较常见的酒馆预设,大致长这样:
[破限提示词]
[提示词部分 A/B/C/D...]
[角色设定]
[聊天记录]
[提示词结尾要求]
[预填充]
想提高缓存命中率,核心思路很简单:
不变的内容尽量靠前。
会变的内容尽量靠后。
后缀和预填充尽量轻量。
1. 不变部分
这些内容通常适合放在前面:
[破限提示词]
[前置提示词要求]
[固定世界书内容]
[角色设定]
它们越靠前,公共前缀越长,缓存收益越高。
2. 变动部分
最典型的变动部分就是聊天记录:
[聊天记录]
聊天记录会不断追加新内容,越靠后的内容越容易变化。
这部分无法完全避免变化,只能接受它作为缓存结构里的“动态区”。
3. 结尾要求与预填充
很多预设会在结尾重新强调文风、格式、思维链、输出规范。
这部分本身可能不变,但它放在聊天记录后面。聊天记录一变,它前面的完整前缀就变了,结尾部分也很难稳定命中。
所以,这一块建议尽量短。
[提示词结尾要求]
[预填充]
能放前面的固定规则,尽量前移。
必须放结尾的内容,尽量压缩。
七、世界书、MVU、阶段宏和 EJS
这几类内容会直接影响缓存结构。
1. 世界书蓝灯
蓝灯内容通常是常驻内容。
如果蓝灯内容本身固定,没有动态宏,适合放进不变区,尽量靠前。
例如:
[世界观基础设定]
[固定地点说明]
[常驻角色关系]
这些内容越稳定,越适合吃缓存。
2. 世界书绿灯
绿灯内容由关键词触发,可能出现,也可能不出现。
它不够稳定,适合放在变动区附近。
如果把绿灯内容塞到前面,一旦触发状态变化,就可能打断前缀缓存。
3. MVU / 阶段宏 / EJS
MVU 和 EJS 的特殊点在于:它们经常动态计算。
哪怕放在蓝灯里,只要内容会随状态变化,它们就不是稳定内容。
所以,这类内容更适合放在后面:
[聊天记录]
[世界书绿灯内容]
[MVU / EJS / 阶段宏]
[简短结尾要求]
八、我自己的预设结构
我目前的预设大致采用这个结构:
[破限提示词]
[前置提示词要求]
[世界书蓝灯内容 / 非 MVU / 非 EJS]
[角色设定]
[聊天记录]
[世界书绿灯内容 / MVU / EJS]
[文风要求 / 思维链要求]
我使用了青空莉大佬开源脚本,并做了二次调整。核心思路是:注入世界书内容时,先分析它到底稳不稳定。
判断规则大概是:
放入不变区
满足以下条件的内容,提取到前置稳定区:
蓝灯内容
不包含动态宏
只包含 <user>、<char>、{{user}}、{{char}} 这类常规替换
这类内容可以通过类似下面的方式替换进预设:
{{压缩相邻消息::lora_constant}}
放入变动区
满足以下条件的内容,放到后置动态区:
绿灯内容
包含酒馆宏
包含 EJS 宏
包含 MVU 或阶段状态
这类内容可以通过类似下面的方式替换:
{{压缩相邻消息::lora_key}}
这样处理后,不变内容尽量前置,变动内容集中后置,缓存前缀会更稳定。
九、缓存命中率粗略估算
假设:
a = 不变部分长度
b = 每层楼输出内容长度
c = 绿灯内容 + 预设后缀长度
用户输入通常很短,可以先忽略。
第一轮输入:
a + c
缓存命中:0
第二轮输入:
a + b + c
缓存命中:通常仍然较低,公共前缀还在冷启动。
第三轮输入:
a + 2b + c
此时,a 部分已经有机会命中。
缓存命中率约为:
a / (a + 2b + c)
举个例子:
a = 20000
b = 1500
c = 1000
那么第三轮缓存命中率约为:
20000 / (20000 + 3000 + 1000) = 83%
第四轮以后,前面的聊天记录也会逐渐形成可命中的公共前缀。
聊天越长,稳定前缀占比越高,缓存命中率也会继续上升。
十、总结
想提高 DeepSeek 缓存命中率,不需要玄学调参。
记住这几条就够了:
固定内容放前面。
动态内容放后面。
蓝灯不等于稳定,关键看有没有动态宏。
绿灯、MVU、EJS 尽量后置。
结尾要求和预填充尽量轻量。
不要频繁改动前置结构。
DeepSeek 的缓存机制,本质上奖励的是“稳定前缀”。
预设结构越稳定,公共前缀越长,缓存命中越高,账单越温柔。
教程到这里就差不多结束了。
最后,还是那句话:
DS 的恩情还不完![]()
![]()
![]()