4 月 26 日消息,据科技媒体 The Decoder 今天报道,查尔姆斯理工大学、沃尔沃集团研究团队最近在一篇论文指出,AI 智能体并不会让软件工程师失业。反而还可以通过“半可信执行栈”扩展工作范围。
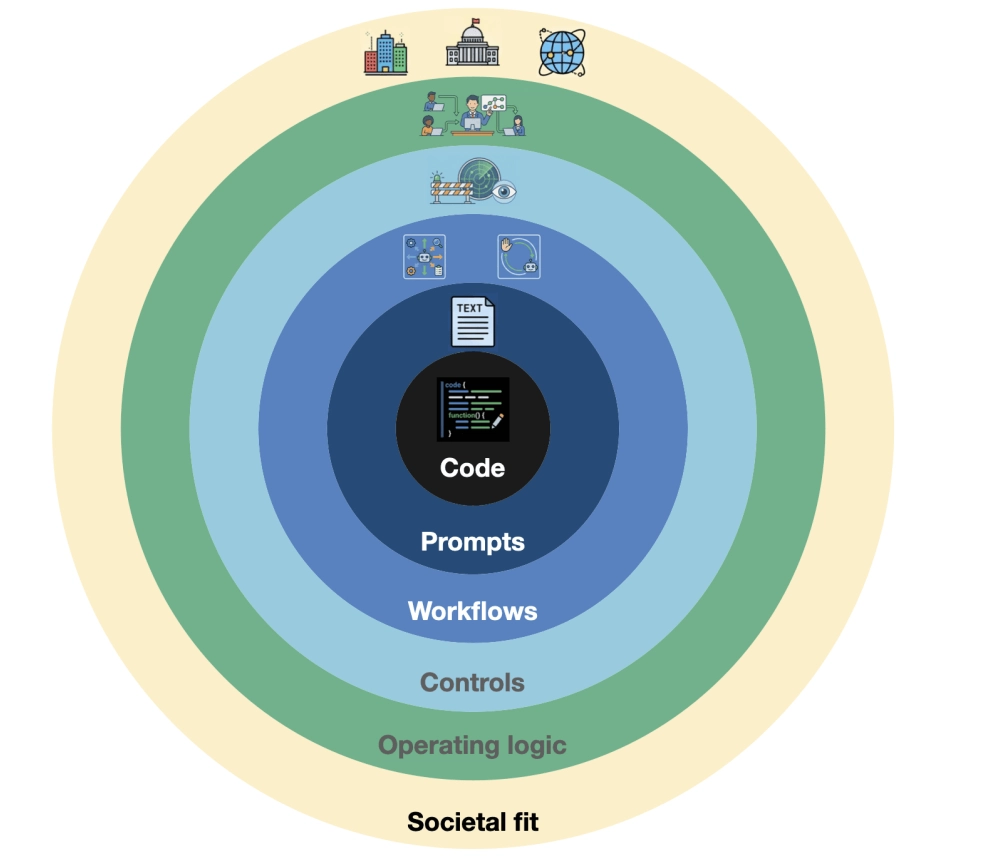
据报道,研究团队首先提出了一个由六环组成的“半可信执行栈”(semi-executable stack)模型,将传统代码向外延伸,触达欧盟 AI 法案等社会因素。
论文中的“半可信执行栈”由六个环组成:经典代码、提示词和自然语言规范、智能体工作流编排、控制系统、运营组织逻辑、社会与制度适配。
目前,软件工程师主要在经典代码(注:第一环)、提示词(第二环)工作;而智能体工作流(第三环)、安全围栏(第四环)和决策流程(第五环)正在成为高优先级工程对象;社会制度适配(第六环)则决定 AI 的实际执行。
研究者认为,目前 AI 智能体最大的漏洞集中在第五环和第六环,人们已经写了几十年代码,但 AI 决策、制度适配等宏观流程仍然缺失,大多数研究仍然集中在修复错误、测试 AI 等。
学者表示,AI 不需要拥有顶尖人类学者的水平,只需要够用就行。大量部署 AI 带来的价值高于部分顶级专家。
此外,研究人员并没有忽视 AI 的“幻觉”问题,他们认为这更凸显了测试、监控的必要。人类在未来仍存在价值。
经典老调重弹,真正写过生产级AI集成的都知道问题在哪。论文里这个"半可信执行栈"模型看着挺唬人,但第六环的"社会制度适配"根本就是个黑箱,欧盟法案随时变,今天合规明天可能就踩线。我团队去年就卡在这个环节,光法务评估就花了三个月,AI生成的代码再漂亮也得打回来重写。说到底是研究环境和现实脱节了,学术界总爱画大饼。
刚转行做前端三个月,看到这个"提示词和自然语言规范"是第二环,有点困惑。是不是以后我们写需求文档的方式要彻底变了?我不太确定现在该学些什么才不会被淘汰,有没有过来人给指条路?
论文写得挺漂亮,但实际我同事已经被优化了三个,工作边界拓展个寂寞
先把你们项目的单元测试覆盖率提到80%以上再谈AI接管吧,基础都没打好。
上周用Copilot生成了一段数据库连接池配置,本来以为省事了,结果半夜报警,连接泄漏。排查才发现AI没考虑我们特定的超时重试机制。具体操作:1. 在prompt里明确写出所有边界条件和异常处理要求;2. 生成的代码必须走完整的测试用例,尤其是压力测试;3. 关键配置项手动复核一遍。不能完全相信它。
笑死,又来这种帖子了,每次都是“不会失业”“拓展边界”,然后隔壁组裁员名额下来第一个砍的就是基础开发岗。建议小编下次直接贴培训班广告,更实在。
这个“半可信执行栈”的图里,把“社会与制度适配”放在最外环,这个定位很有意思。想追问一下研究者,如果不同国家的制度要求冲突(比如欧盟的AI法案和某国的数据本地化要求),这个模型建议的适配优先级是什么?是设计时就做多套逻辑,还是运行时动态切换?论文里有更具体的案例讨论吗?
让我想起了去年做的一个物联网项目,当时想用AI智能体优化设备指令下发策略。我们卡在了论文里说的第五环“决策流程”上,AI给出的节能策略在模拟环境里跑分很高,但一到真实工厂环境,遇到网络抖动、老旧设备协议不标准等问题,决策就完全乱套了。最后还是工程师靠经验写死了几套降级方案。感觉现在AI离处理这种现实世界的混乱和不确定性还差得远,学者们说得轻松,真落地掉层皮。
我已经感觉边界扩了 现在不写代码就盯着prompt调一天
Copilot不知道自定义重试机制是常态,得提示词带上
配置类代码踩重试机制坑太典型,AI不清楚你的业务约束,必须人工兜底。