今天这组技能,整体质量很高,覆盖了BI分析、AI协作开发、网页内容提取、健康数据整合、长期记忆增强几个方向,每日最新github技能分享开始了开始了,可以看看有没有你需要的呢?
1.Engine
让AI助手直接读写Power BI模型,用自然语言完成DAX、关系管理和度量值修改。
GitHub地址:https://github.com/maxanatsko/mcp-engine-public
Engine是一款面向Power BI场景的强力工具,它把AI助手和Power BI模型真正打通了。通过它,Claude、ChatGPT这类AI不只是“帮你写建议”,而是可以程序化读取模型结构、执行DAX查询、创建或修改Measures、管理表关系,甚至参与更复杂的分析工作。
这类工具的价值很直接。以前很多Power BI操作依赖专业人员手动完成,修改成本高,验证流程长。现在借助Engine,很多工作可以直接通过自然语言驱动完成,而且还支持回滚、测试、部署前验证,整个改动过程更可控,也更适合在真实业务环境里使用。
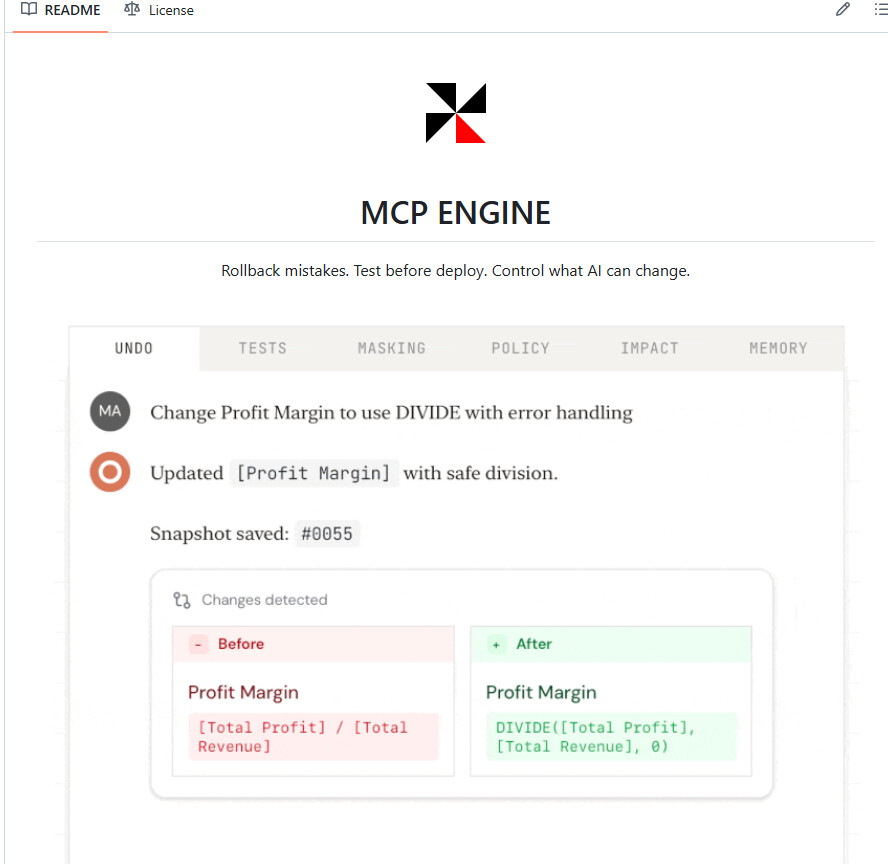
亮点功能:
-
支持AI助手程序化操作Power BI模型
-
支持AI读取模型结构并执行DAX查询
-
支持通过自然语言创建和修改Power BI度量值
-
支持AI辅助管理模型中的关系配置
-
支持版本控制、回滚和部署前测试
适用场景:
-
让非技术用户也能通过自然语言调整Power BI模型
-
在正式部署前验证AI做出的模型改动
-
自动化完成Power BI模型开发和优化流程
2.AI Agents Orchestrator
一套面向开发场景的AI智能体编排系统,既能跑流程,也能让多个角色型Agent协作解决复杂问题。
GitHub地址:https://github.com/hoangsonww/ai-agents-orchestrator
AI Agents Orchestrator提供了两套独立但很强的系统。一套是基于步骤的Orchestrator,适合实现“开发-审查-优化”这种固定流程;另一套是Agentic Team运行时,更像一个可以自由沟通的AI团队,让项目经理、开发、测试这些角色型Agent直接协作。
它的想象空间很大,因为它并不绑定某一个模型,而是可以统一编排Claude、Codex、Gemini、Copilot、Ollama、llama.cpp等多种AI编码助手。加上图谱式上下文记忆、可复用技能、MCP工具库,这已经不是单一Agent工具,而是偏向企业级AI开发基础设施了。

亮点功能:
-
提供两种系统:步骤型编排器和自由通信型Agent团队运行时
-
基于图谱的上下文系统,支持BM25+语义检索的混合搜索
-
内置9个专业Agent、22个可复用技能、34+MCP工具
-
可统一调度Claude、Codex、Gemini、Copilot、Ollama、llama.cpp
-
提供REPL/CLI接口和Vue/Nuxt可视化界面
适用场景:
-
自动化完成从编码到Review再到Refine的多阶段开发流程
-
让多个专业AI角色协作解决复杂编程问题
-
搭建具备持续学习能力的企业级智能体系统
3.Qt Web Extractor
一个适合AI和数据处理场景的网页提取引擎,擅长抓取现代动态网页和PDF,并直接输出结构化Markdown。
GitHub地址:https://github.com/wszqkzqk/qt-web-extractor
Qt Web Extractor的核心能力在于“把复杂网页内容提取得更干净”。它基于Qt WebEngine,也就是Chromium内核,能更好地处理JavaScript重度页面、Cookie、会话状态和客户端渲染内容。对于很多传统HTTP抓取器抓不全、抓不准的页面,它会更稳定。
它特别适合接入AI工作流。因为它不仅能抓到内容,还能直接转成结构化Markdown,这对大模型、Agent、知识整理、自动化数据管道都非常友好。不需要上完整浏览器自动化,成本更轻,效果也够用。

亮点功能:
-
提供CLI、Python库和HTTP REST服务三种接口
-
支持完整JavaScript渲染、Cookie和会话处理
-
支持无头运行,依赖相对轻量
-
输出适合LLM使用的智能Markdown格式
-
支持Qt PDF文本提取和自动识别
适用场景:
-
将渲染后的网页内容直接喂给LLM
-
接入AI Agent、爬虫系统和自动化脚本
-
作为Open WebUI等平台的外部网页加载器
4.FitnessSyncer
一个聚合50多种健康和运动数据源的API服务,帮助开发者更轻松地接入健康数据场景。
GitHub地址:https://github.com/fitnesssyncer/fitnesssyncerapi
FitnessSyncer提供的是一套基于OAuth的REST API,并且已经给出了OpenAPI规范文件。对开发者来说,这种工具最大的意义就是不用再一个个平台一个个平台地单独接。只要接入FitnessSyncer,就能统一访问多个健康和运动数据来源,把复杂接入成本压下来。
它还支持推送和拉取两种通知模型,也提到了MCP Server的集成方式。对于要做运动健康类应用、数据同步工具、个人健康面板的人来说,这样的能力会很省事,开发节奏也能快很多。
亮点功能:
-
提供OpenAPI v3规范,方便快速生成代码
-
基于OAuth的REST API,安全访问健康数据
-
聚合50多个健康与健身数据源
-
支持Push和Pull两种数据变更通知模式
-
提供MCP Server,便于进一步集成
适用场景:
-
构建需要综合健康和运动数据的应用
-
通过单一API整合多个健康服务
-
自动同步数据并接收变更通知
5.AI Memory
给AI编码助手补上长期记忆能力,让它跨会话、跨平台记住项目背景、架构决策和用户偏好。
GitHub地址:https://github.com/beach55607-max/mcp-memory-server
AI Memory解决的是很多人都深有体会的问题:AI每次开新会话,像失忆一样。之前讨论过的架构方案、踩过的坑、已经确认的偏好,往往又要重新讲一遍。这个工具就是为了补齐这块短板,让AI拥有可持续的语义长期记忆。
它支持自然语言搜索历史记忆,也支持自动归档、去重、整合,还强调对关键知识的“Absolute Truth”保护。部署方式也比较友好,可以一次性部署到Cloudflare Workers上免费使用。对于频繁在Claude Code、ChatGPT、Cursor、Gemini CLI之间切换的人来说,这类工具非常有价值。

亮点功能:
-
支持自然语言语义搜索,召回过去的重要信息
-
支持自动归档、去重和记忆整合
-
支持AI主动保存重要发现、结论和决策
-
支持跨平台、跨会话共享记忆
-
提供“Absolute Truth”保护机制,保存关键不可变知识
适用场景:
-
回忆过去会话中的调试方案和架构决策
-
让AI在不同平台中持续遵循用户习惯和偏好
-
保持多个AI助手之间的项目上下文一致性
6.Leadhunt
一个面向本地商业线索挖掘的工具,专门帮助用户发现存在数字化问题的本地商家,并完成后续触达和管理。
GitHub地址:https://github.com/forgeai-cmd/leadhunt
Leadhunt的思路很直接,不是单纯给你一堆商家名单,而是先帮你找到“更需要服务的客户”。它会针对指定城市和行业,对商家的网站和线上表现做一套29项数字化审计,覆盖技术、SEO、分析、转化、本地化和社交等多个维度,最后给出0到100的评分,用来判断这家商家是否更有合作机会。
更完整的一点在于,它不仅负责“找”,还把后面的触达和管理也一起打包了。你可以用CLI做本地线索挖掘,也可以用SaaS面板管理潜在客户、发送个性化审计报告,并通过邮件、WhatsApp、短信、AI语音电话等方式做多渠道外联。这对于营销团队、销售团队、本地服务商来说,效率会高很多。
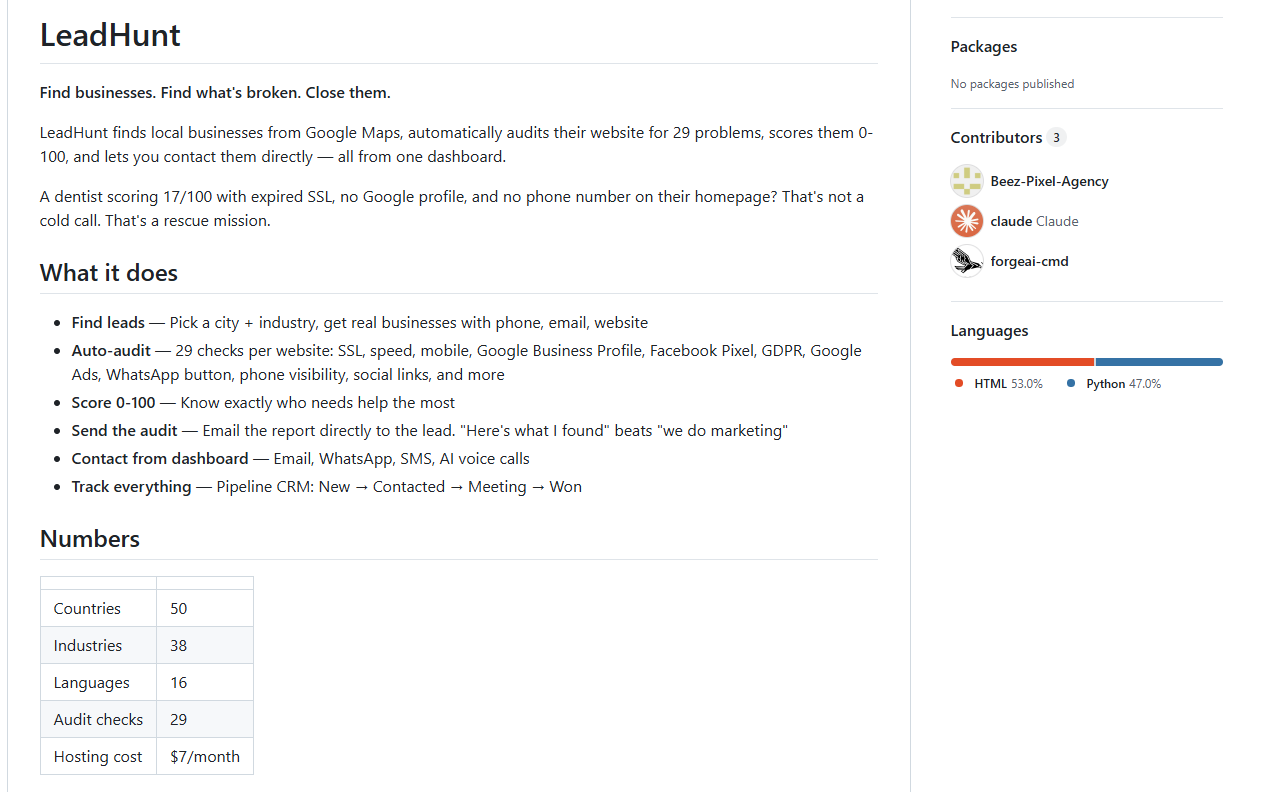
亮点功能:
-
支持邮件、WhatsApp、短信、AI语音电话等多渠道触达
-
提供29项网站与线上表现审计
-
自动发现本地商家并给出0-100评分
-
支持可自定义的触达模板和动态占位符
-
内置CRM流程管理和排期能力
适用场景:
-
本地服务商自动化寻找和筛选潜在客户
-
营销机构挖掘存在数字化问题的新客户
-
销售团队针对本地商家做定向外联和转化
7.Obsidian LLM Wiki
把你的Obsidian知识库升级成一个可被AI直接读写、搜索、整理和编译的智能知识系统。
GitHub地址:https://github.com/2233admin/obsidian-llm-wiki
Obsidian LLM Wiki受Karpathy提出的LLM Wiki思路启发,目标是让你的Obsidian Vault不只是个人笔记仓库,而是变成一个真正可供AI使用的知识底座。像Claude Code、Cursor、Windsurf这类支持MCP的AI工具,都可以直接接入你的笔记系统,读取、搜索、写入和编排内容。
这个工具的价值不只是“让AI看笔记”,而是让AI帮你持续维护整个知识体系。它支持全文搜索、标签和frontmatter查询、图谱关系分析,还能在Obsidian关闭时通过文件系统继续工作。无论是做知识沉淀、资料整理,还是长期研究型写作,这类工具都会很有帮助。
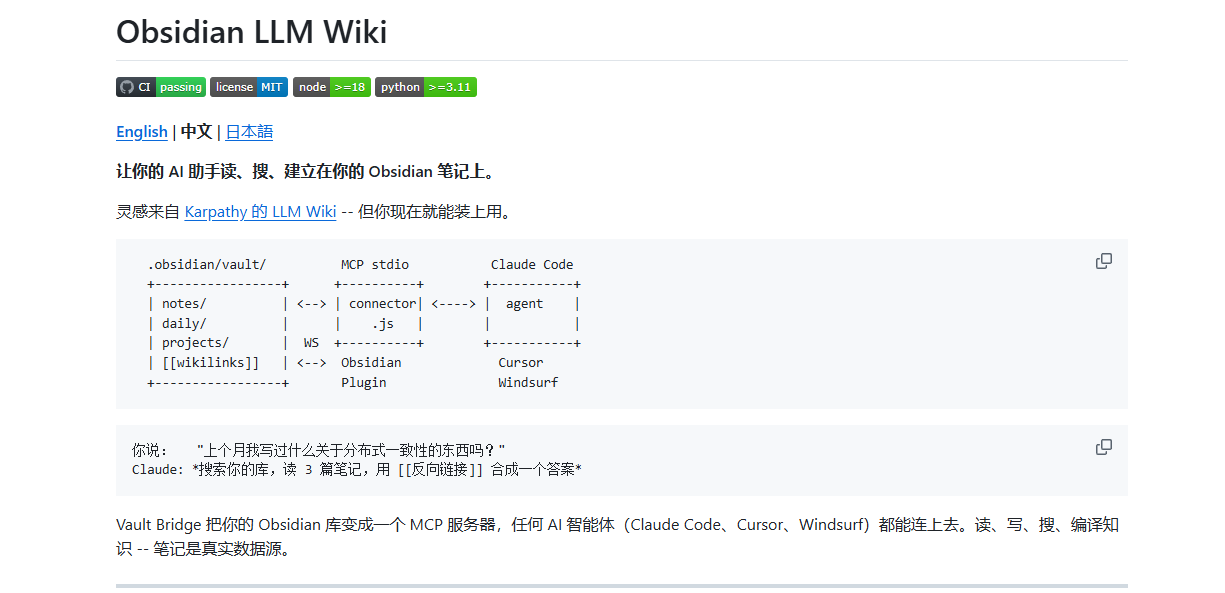
亮点功能:
-
支持Claude Code、Cursor、Windsurf等MCP兼容Agent接入
-
支持全文搜索、标签/frontmatter查询、链接与反向链接分析
-
即使Obsidian关闭也能通过文件系统继续工作
-
支持安全地读取、创建、修改、删除笔记
-
支持Karpathy风格的知识编译流程,自动把原始资料整理成互相关联的Wiki
适用场景:
-
自动把论文、文章、零散笔记整理成结构化知识库
-
用AI维护Vault健康状态,查孤立笔记、坏链和元数据一致性
-
让AI基于整个Obsidian库回答具体主题问题
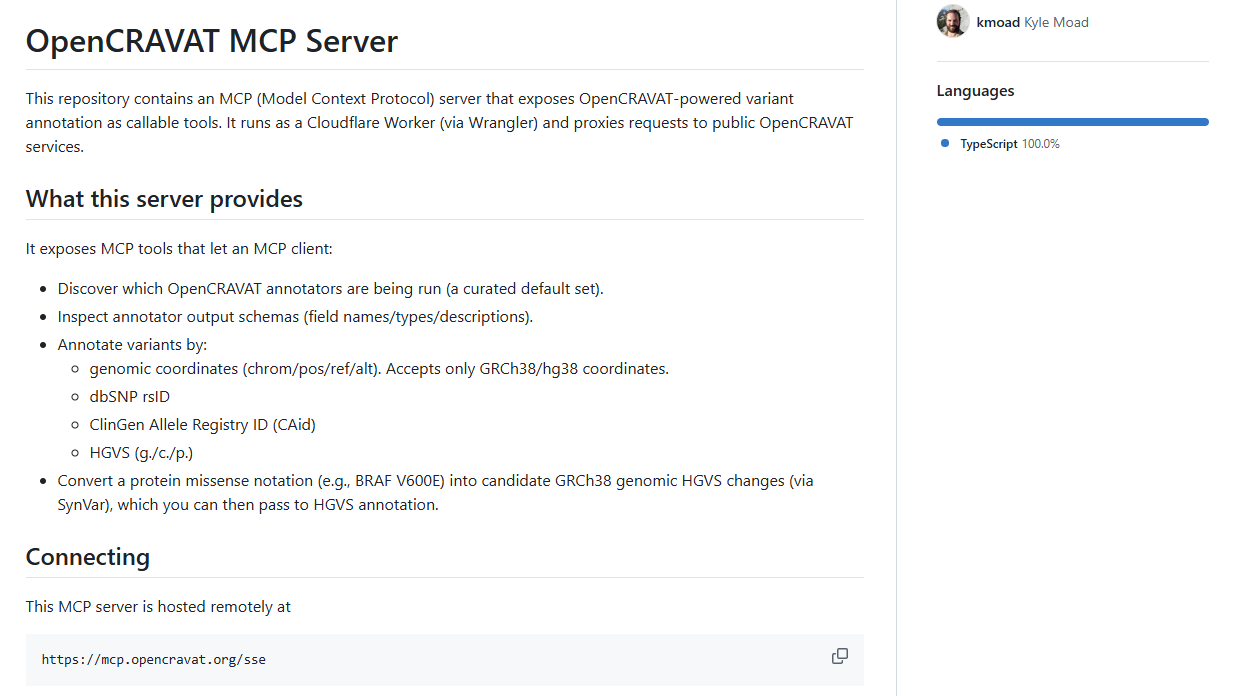
8.OpenCRAVAT
把OpenCRAVAT的基因变异注释能力封装成MCP工具,方便直接接入AI聊天和科研工作流。
GitHub地址:https://github.com/karchinlab/oc-mcp
OpenCRAVAT MCP Server本质上是一座桥,把OpenCRAVAT原本强大的变异注释能力,转换成可以通过MCP调用的工具集合。这样一来,AI客户端就可以直接发现可用注释器、查看输出结构,并基于不同输入格式做变异注释。
它支持GRCh38坐标、dbSNP rsID、ClinGen Allele Registry ID、HGVS标注等多种输入形式,还整合了SynVar,可以把蛋白错义突变写法转成潜在的GRCh38基因组HGVS变更。对于基因研究、生物信息分析和科研辅助AI场景来说,这种工具相当有实用价值。
亮点功能:
-
可发现OpenCRAVAT注释器并查看输出结构
-
支持GRCh38坐标、dbSNP rsID、ClinGen Allele Registry ID等多种输入
-
支持通过HGVS格式进行变异注释
-
支持把蛋白错义突变转成GRCh38基因组HGVS变化
-
可部署到Cloudflare Worker,也支持本地运行
适用场景:
-
在Claude、ChatGPT等AI平台中直接进行基因变异注释
-
将蛋白突变快速转换成后续分析所需的HGVS表达
-
为自定义MCP客户端提供遗传变异注释服务
9.Token Scout
帮助AI Agent实时发现可用模型,并根据兼容性、成本和额度动态路由到最合适的LLM。
GitHub地址:https://github.com/jackccrawford/token-scout
Token Scout解决的是一个越来越现实的问题:模型越来越多,平台越来越分散,怎么让Agent自动挑到最合适的那个。它会同时查询云端模型提供商和本地Ollama实例,找到当前可用模型,再根据工具调用能力、上下文窗口、推理格式、价格和额度限制做筛选。
它不是简单列个清单,而是直接返回可调用的端点,让Agent无需再经过额外代理或中间层就能使用模型。对多模型协同、成本控制、本地优先工作流这类场景来说,这个能力会非常关键。
亮点功能:
-
直接返回可调用模型端点,减少中间层开销
-
实时按工具调用、上下文窗口、推理格式过滤兼容模型
-
动态跟踪额度使用,避免超限
-
支持从云端和本地Ollama发现可用模型
-
支持按免费、低成本、高性能策略控制推理成本
适用场景:
-
优化AI编码助手的模型成本和性能选择
-
构建支持动态选模的多模型工作流
-
实现本地优先的AI运行方案
-
管理多Agent集群中的模型分配
10.AI Answer Copier
一个把AI生成内容快速转换成多种可交付格式的MCP工具,适合文档导出、Markdown修复和结构分析。
GitHub地址:https://github.com/xjtlumedia/mcp_markdown_formatter
AI Answer Copier针对的是一个非常常见但很费时间的问题:AI已经把内容写出来了,真正把它整理成能用的格式,反而还要花不少时间。这个工具就是用来消除这一步摩擦的。它可以把Markdown内容快速转换成PDF、DOCX、HTML、CSV、XLSX以及多种平台格式,也能修复损坏的Markdown,做文档结构分析。
对于老师、内容运营、企业文档处理、知识整理场景来说,这类工具会非常顺手。内容依然在AI聊天界面里完成,不需要来回复制折腾格式,整个交付过程更连贯,也更省时间。
亮点功能:
-
支持23+文档格式和10+平台格式导出
-
支持Markdown分析、修复、lint和结构提取
-
支持数学公式和代码高亮
-
通过MCP协议无缝接入AI助手
-
本地运行,数据更可控
适用场景:
-
把AI生成的内容导出成LMS所需CSV、报告用DOCX等格式
-
修复和规范化大模型生成的Markdown文本
-
分析文档结构、提取链接并生成统计信息
今天这期技能分享就到这里,发现了有啥好用有趣的技能,我也会第一时间分享出来,大家也别藏着掖着啦,有啥宝藏技能欢迎在评论区互动![]()