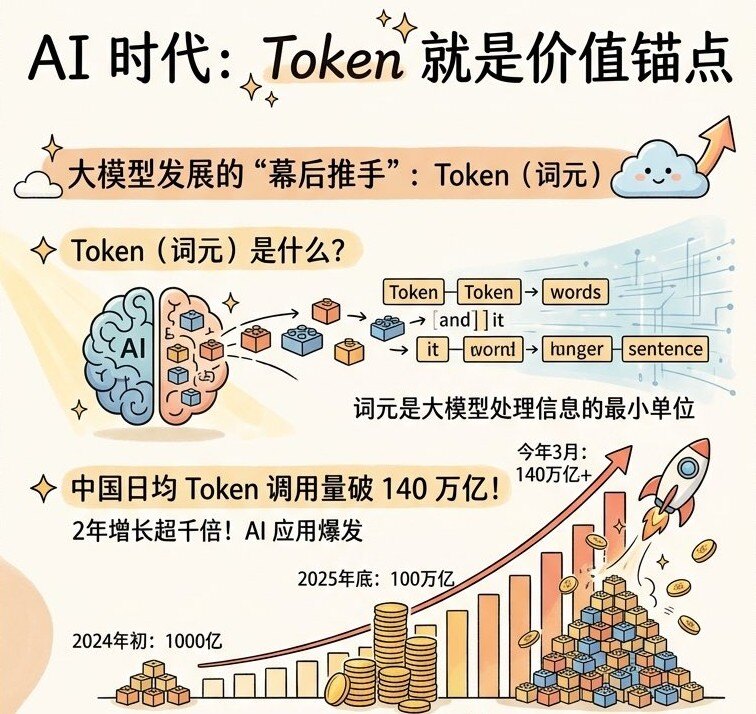
近期,官方对Token一词进行了正式定义,官方中文翻译名为:词元。而与此同时,就在昨日,人民日报同步披露重要数据。我国日均词元调用量已突破 140 万亿大关。词元已经渗透进生产日常的各个角落。AI 交互的基础正是词元,理解词元,掌控词元,便能站稳AI时代的桥头堡,那么到底什么叫词元?当下又有有哪些词元消耗低的agent推荐?这篇文章带你搞懂,解决你所有的词元疑惑。
一、究竟什么是词元?
大模型处理信息存在的最小单元,这个单元即为词元(Token)。词元具备可计量、可定价、可交易的数字资产特征。频繁调用大模型,必定绕不开词元结算。别把词元简单视作纯粹扣费损耗。词元实则为AI大模型吞吐处理信息的最小信息单元。智能时代浪潮下,词元具备了可计量、可定价、可交易的硬核资产特征。当下,围绕词元调用、词元分发、词元结算,一套崭新价值体系正加速演进成型,化作人工智能产业商业化落地的核心引擎。
二、如何节省词元成本?
彻底榨干AI潜能的终极形态当属Agent智能体。Agent深度执行复杂任务,不可避免带来海量词元开销,其词元消耗量远超普通闲聊对话。

大家痛心高昂的词元账单,急需一款极致压缩词元成本的智能工具。这里重磅安利一款超低词元消耗的Agent神器。
三、Molili低词元消耗的代表agent
寻找词元消耗低的 Agent。推荐这款国内首个 OpenClaw 中文版:当贝Molili(www.molili.com.cn)。内置国内主流模型 Kimi、MiniMax、DeepSeek。核心优势显著。相比原版OpenClaw,吞噬词元的无底洞,Molili的低词元消耗优势可谓显著!
内置顶流模型:原生聚合国内主流大模型阵列,Kimi、MiniMax、DeepSeek一网打尽,随时切换输出优质词元。
极致词元省钱:主打超低词元消耗特性。实测对比原版OpenClaw,Molili词元消耗量直接锐减两倍!堪称词元省钱界天花板。

海量技能武装:配套8000+庞大技能商店,海量插件即插即用,轻松实现词元驱动下的技能自由。
硬核隐私护航:构建三重严密安全防护网,全方位死守隐私底线,确保本地设备运行词元绝对安全。
创新多体架构:首创“三省六部制”运转逻辑,自带庞大复杂的协同多Agent系统,可玩性直接拉满。不同部门精准匹配专属职责,轻松拿捏复杂场景下的Agent灵活调动、词元精准分配。

小白轻松驾驭:不仅服务极客。更要普惠 AI 能力。Molili安装极其简便。一键安装。一分钟搞定。拒绝复杂难懂的命令行。简单清楚的 UI可视化。一句指令搞定各种复杂工作。
四、一图看懂国内各种龙虾agent产品
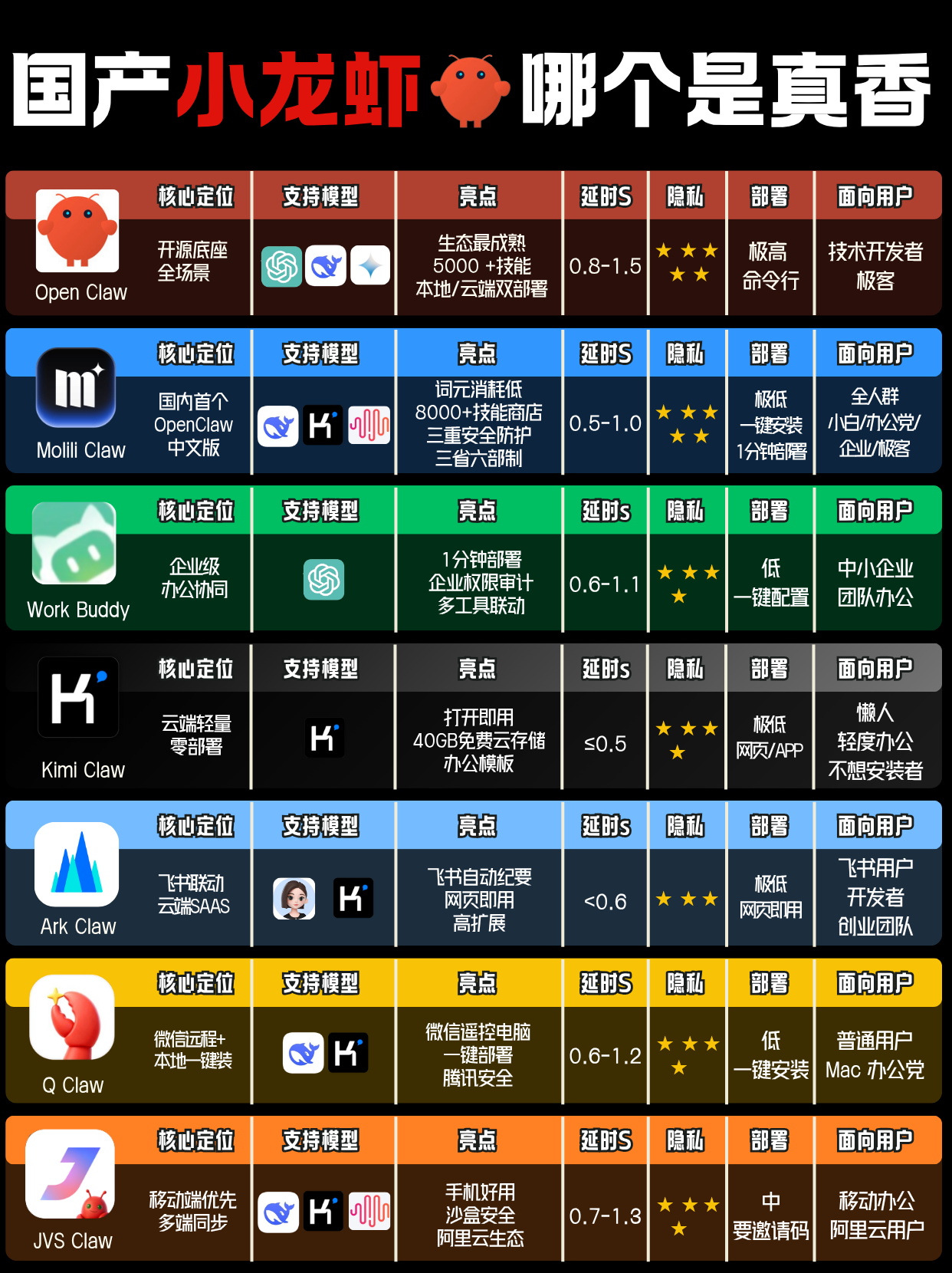
所以节省词元,就是节省成本,词元消耗量实测对比,Molili 表现优异,十分省钱,小白首选。高效率,低词元。Molili绝对是全网省词元、控成本的最佳选择!